
语音识别技术在语音助手和机器人、通过辅助医疗或教育解决现实世界问题等方面越来越受欢迎。这有助于实现全球 speech AI 接入的民主化。随着为独特的新兴语言标记的数据集变得越来越广泛,开发人员可以轻松、准确、经济地构建 AI 应用程序,以增强本地区的技术开发和体验。
Kinyarwanda 是卢旺达、乌干达、刚果民主共和国和坦桑尼亚 980 万人的母语,全球共有 2000 多万人使用。
2022 年 4 月, Mozilla Common Voice (MCV) ,一个众包项目,旨在使语音识别向所有人开放和可访问,对构建基尼亚卢旺达数据集做出了重大贡献,详见文章 Lessons from Building for Kinyarwanda on Common Voice 。这是一个 57 GB 的数据集,有 2000 多小时的音频,是 MCV 平台上最大的数据集。
为了给开发人员带来工作和数据集的价值,在此数据集上训练了一个自动语音识别 ( ASR )模型,该模型在发布的检查点上实现了最先进的性能。
本文概述了使用 NeMo ASR 工具包的培训过程。它简要介绍了数据集面临的挑战,使用 byte-pair encoding 将字符转换为更长的单位,以及改进模型性能的训练过程。开发者可以参考 GitHub 上的 step-by-step tutorial 了解参考代码和详细信息。
获取数据集
MCV 拥有最大的公开多语言数据集。您可以从 Mozilla Common Voice Hub 下载特定语言的数据集。
在用于模型的 Kinyarwanda 数据集中,有 1404853 个句子被预先分解为 train/dev/test 数据。数据集中的每个条目都包含一个唯一的 MP3 文件和相应的信息,如文件名、转录和 TSV 格式的元信息。
NeMo ASR 要求数据包括单个音频文件中的一组发音,以及描述数据集的清单,以及每行一个发音的信息。
一旦下载了数据集,在培训分割中, TSV 文件将转换为 JSON 清单, MP3 文件将转换成 WAV 文件,这是 NeMo 工具包的推荐格式。然后分别对测试和开发数据重复相同的步骤。
清单格式如下所示:
{"audio_filepath": "/path/to/audio.wav", "text": "the transcription of the utterance", "duration": 23.147}数据预处理
在训练模型之前,数据需要预处理,以减少模糊性和不一致性,并使数据易于解释。此模型的预处理步骤为:
- 用空格替换所有标点符号(撇号除外)
- 将不同类型的撇号[””替换为 1
- 使所有文本小写 确保一致性
- 用变音符号替换罕见字符 ( [éèëēê] → e 、 例如)
- 删除所有剩余的词汇表字符
(例如,组合拉丁字母、空格和撇号)
由于 99% 的数据集的音频持续时间为 11 秒或更短,建议在预处理期间将最大音频持续时间限制为 11 秒,以加快训练速度。
最后的基尼亚卢旺达语抄本由预处理后的拉丁字母、空格和撇号组成。
子字标记化
可以训练基于字符的 ASR 模型,但它们会将每个字母视为一个单独的令牌,生成输出需要更多的时间。使用更长的单位可以提高质量和速度。
这个过程包括一个名为 byte-pair encoding 的标记化算法,它将单词拆分为子标记,并用一个特殊符号标记单词的开头,这样很容易恢复原始单词。
为了简化这个过程, NeMo 工具包通过将标记化器传递到模型配置来支持动态子字标记化,因此无需修改转录本。这不会影响模型性能,并且可能有助于在不重新训练令牌化器的情况下适应其他域。
请访问 GitHub 上的 NVIDIA/NeMo ,了解 NeMo ASR 子字标记化的详细说明和教程。
培训模式
两种方法导致训练模型。第一种方法涉及使用两种模型架构从头开始训练模型: Conformer CTC 和 Conformer Transducer 。第二种方法包括
从不同的预训练检查点微调 Kinyarwanda Conformer 传感器模型。
要训练 Conformer CTC 模型,请使用 speech_to_text_ctc_bpe.py 和默认配置 conformer_ctc_bpe.yaml 。要训练 Conformer 传感器模型,请使用 speech_to_text_rnnt_bpe.py 和默认配置 automatic speech recognition 。
对于微调,请将预训练的 STT_EN_Conformer_Transducer model 用于非自监督的检查点。使用 SSL_EN_Conformer_Large 作为 NVIDIA GPU Cloud 的自我监督检查点。您可以在 GitHub 上的分步教程中找到有关培训过程的更多详细信息。
下面提供了自监督检查点初始化( SSL _ EN _ Conformer _ Large )的参考代码。
import nemo.collections.asr as nemo_asr
ssl_model = nemo_asr.models.ssl_models.SpeechEncDecSelfSupervisedModel.from_pretrained(model_name='ssl_en_conformer_large')
# define fine-tune model
asr_model = nemo_asr.models.EncDecCTCModelBPE(cfg=cfg.model, trainer=trainer)
# load ssl checkpoint
asr_model.load_state_dict(ssl_model.state_dict(), strict=False)
del ssl_model
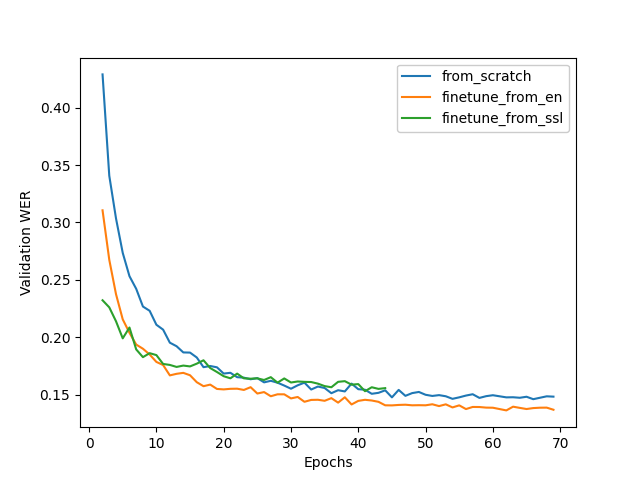
图 1 显示了训练动态的比较。微调方法对于训练来说既快速又容易,同时还可以加快收敛速度和提高质量。
测试结果
在构建模型时,目标是在转录语音输入的同时最小化字错误率( WER )。简单地说,单词错误率是错误数除以单词总数。 它通常用于测试模型的性能,但不应成为唯一的标准,因为噪声、回声和口音等超出范围的变量会对语音识别产生重大影响。
还考虑了字符错误率( CER )。 CER 给出了错误预测的字符百分比。我们的模型在基尼亚卢旺达 ASR 模型中 WER 和 CER 的百分比最低(表 1 )。
| Model | WER % | CER % |
| Conformer-CTC-Large | 18.73 | 5.75 |
| Conformer-Transducer-Large | 16.19 | 5.7 |
关键要点
我们使用 NeMo 工具包从头开始构建了两个高质量的基尼亚卢旺达检查站。 Conformer-Transducer checkpoint 具有更好的质量,但 Conformer-CTC 的推理速度是 4x ,因此根据需要,它们都可能有用。
预训练模型的高性能是语音人工智能社区新发展的又一步。最先进的模型可以通过使用更多的数据对其进行微调来进一步改进,这些数据包含更多的方言、口音和稀有词汇,是人们如何使用母语的真实表示。 NVIDIA NeMo 预训练模型是开源的,满足全球民主化和包容性的目标。
额外资源
探索 MVC 计划,为您的语言访问或提供语音数据。有关模型的更多信息,请参阅以下资源:
- 浏览 NeMo ASR Collection on NVIDIA GPU Cloud 并下载模型
- 下载 NeMo pretrained models
- 在 GitHub 上浏览 NeMo toolkit 以获取示例代码、示例和教程
与来自谷歌、 Meta 、 NVIDIA 等的专家一起参加第一届年度 NVIDIA -Speech AI 峰会。 Register now.




