
计算机视觉模型的进步提供了更深入的见解,使我们的生活更加富有成效,我们的社区更加安全,我们的地球更加清洁。
例如,目标检测可以告诉我们患者是在走路还是坐在地板上,但如果患者晕倒了,它却不能提醒我们,我们离目标检测还有很长的一段路要走。新的计算机视觉模型通过处理时间信息和预测动作来克服这些类型的挑战。
从头开始构建这些模型需要人工智能专业知识、大量训练数据和大量计算能力。幸运的是,转移学习使您能够使用这些资源的一小部分构建自定义模型。
在本文中,我们将介绍使用 NGC 目录中的 NVIDIA AI 软件构建和部署计算机视觉应用程序的每个步骤,并在 Google Cloud Vertex AI Workbench 上运行该应用程序。
软件和基础架构
NGC catalog 提供 GPU 优化的 AI 框架、训练和推理 SDK 以及预训练模型,可通过现成的 Jupyter 笔记本轻松部署。
Google Cloud Vertex AI 工作台 是整个 AI 工作流的单一开发环境。它通过与在生产中快速构建和部署模型所需的所有服务深度集成,加速了数据工程。
通过管理管道加快应用程序开发
NVIDIA 和 Google Cloud 已经合作,可以轻松地将软件和模型从 NGC 目录部署到 Vertex AI 工作台。只需单击一下即可使用 Jupyter 笔记本,而无需十几个复杂的步骤,就可以轻松完成。
此快速部署功能以最佳配置在 Vertex AI 上启动 JupyterLab 实例,预加载软件依赖项,并一次性下载 NGC 笔记本。这使您能够立即开始执行代码,而不需要任何专业知识来配置开发环境。
拥有免费积分的谷歌云账户足以构建和运行此应用程序。
Live webinar
您也可以在 6 月 22 日参加我们的 live webinar ,我们将逐步指导您如何使用 NGC 目录和 Vertex AI Workbench 中的软件构建识别人类行为的计算机视觉应用程序。
开始
要跟进,您需要以下资源:
- 登记或签名 进入 NGC 目录
- 登录 Google 云或注册以接收 free credits
软件
- NVIDIA TAO 工具包 :一个 AI 模型适应框架,用于使用自定义数据微调预训练模型,并生成高度精确的计算机视觉、语音和语言理解模型。
- 动作识别模型 :一个五类行动识别网络,用于识别人们在图像中的行为。
- Action Recognition Jupyter Notebook :使用 TAO 工具包的 Action \ u Recognition \ u Net 的一个示例用例。
当您登录到 NGC 目录时,您将看到策划的内容。
NGC 上的所有 Jupyter 笔记本电脑都托管在左窗格的 Resources 下。查找 TAO 动作识别 notebook.
有几种方法可以开始使用此资源中的 Jupyter 笔记本示例:
- 下载资源,设置 GPU 实例(云或本地),并运行 setup 命令启动 Jupyter notebook 。
- 在 笔记本产品页 上或通过 Vertex AI 集合实体 选择 部署到顶点 AI (图 2 )。
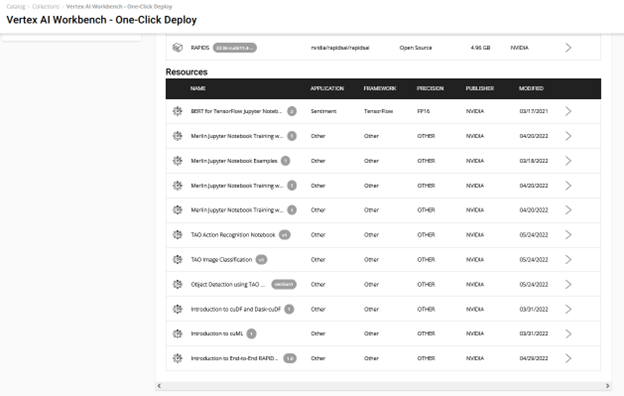
采用快速部署的简单路线。它负责端到端的设置需求,如获取 Jupyter 笔记本、配置 GPU 实例、安装依赖项以及运行 JupyterLab 接口以快速开始开发!通过选择 在 Vertex AI 上部署 进行尝试。
您将看到一个窗口,其中包含有关资源和 AI 平台的详细信息。 Deploy 选项将通向 Google Cloud Vertex AI 平台工作台。
以下信息是预配置的,但可以根据资源的要求进行自定义:
- 笔记本的名称
- 区域
- Docker 容器环境
- 机器类型,GPU 类型,GPU 数量
- 磁盘类型和数据大小
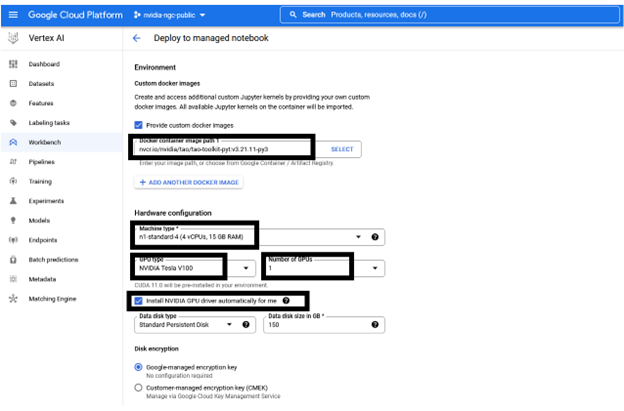
在选择 Create 之前,您可以保持推荐的配置不变或根据需要进行更改。创建 GPU 计算实例和设置 JupyterLab 环境大约需要几分钟的时间。
要启动界面,请选择 Open 、 Open JupyterLab 。该实例加载了拉取的资源( Jupyter 笔记本),并将环境设置为 JupyterLab 中的内核。
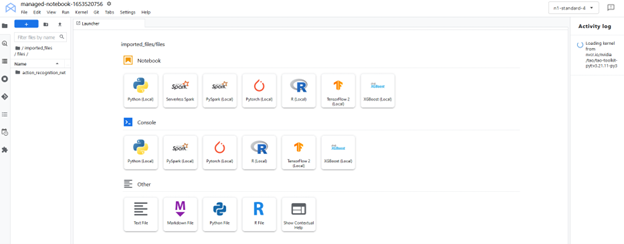
JupyterLab 接口从 NGC 提取资源(自定义容器和 Jupyter 笔记本)。在 JupyterLab 界面中选择定制内核tao-toolkit-pyt。
运行笔记本
这个动作识别 Jupyter 笔记本展示了如何微调识别五种人类动作的动作识别模型。此数据集中有两个操作使用它:fall-floor和ride-bike。
笔记本电脑利用 HMDB51 数据集微调从 NGC 目录加载的预训练模型。该笔记本还展示了如何在经过训练的模型上运行推理,并将其部署到实时视频分析框架 NVIDIA DeepStream 中。
设置环境变量
设置HOST_DATA_DIR、HOST_SPECS_DIR、HOST_RESULTS_D IR 和env-key 变量,然后执行单元格。数据、规格、结果文件夹和 Jupyter 笔记本位于\ action recognition net 文件夹中。
%env HOST_DATA_DIR=/absolute/path/to/your/host/data # note: You could set the HOST_SPECS_DIR to folder of the experiments specs downloaded with the notebook %env HOST_SPECS_DIR=/absolute/path/to/your/host/specs %env HOST_RESULTS_DIR=/absolute/path/to/your/host/results # Set your encryption key, and use the same key for all commands %env KEY = nvidia_tao
运行后续单元格下载 HMDB51 数据集并将其解压缩到$HOST_DATA_DIR。预处理脚本剪辑视频并从中生成光流,光流存储在$HOST_DATA_DIR/processed_data 目录中。
!wget -P $HOST_DATA_DIR "https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/hmdb51_org.zip" !mkdir -p $HOST_DATA_DIR/videos && unzip $HOST_DATA_DIR/hmdb51_org.zip -d $HOST_DATA_DIR/videos !mkdir -p $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/fall_floor.zip -d $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/ride_bike.zip -d $HOST_DATA_DIR/raw_data
最后,将数据集拆分为 train ,并通过运行以下代码单元示例来测试和验证内容,如 Jupyter 笔记本中所示:
# download the split files and unrar !wget -P $HOST_DATA_DIR https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/test_train_splits.zip !mkdir -p $HOST_DATA_DIR/splits && unzip $HOST_DATA_DIR/test_train_splits.zip -d $HOST_DATA_DIR/splits # run split_HMDB to generate training split !cd tao_toolkit_recipes/tao_action_recognition/data_generation/ && python3 ./split_dataset.py $HOST_DATA_DIR/processed_data $HOST_DATA_DIR/splits/test_train_splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train $HOST_DATA_DIR/test
验证最终测试和列车数据集:
!ls -l $HOST_DATA_DIR/train !ls -l $HOST_DATA_DIR/train/ride_bike !ls -l $HOST_DATA_DIR/test !ls -l $HOST_DATA_DIR/test/ride_bike

下载预训练模型
您可以使用 NGC CLI 获取经过预训练的模型。有关更多信息,请转至 NGC ,并在导航栏上选择 SETUP 。
!ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
检查下载的模型。您应该看到resnet18_3d_rgb_hmdb5_32.tlt和resnet18_2d_rgb_hmdb5_32.tlt。
print("Check that model is downloaded into dir.")
!ls -l $HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0
培训规范
在“等级库”文件夹中,可以找到与训练、评估、推断和导出功能相关的不同等级库文件。选择train_rgb_3d_finetune.yaml文件,您可以更改此规范文件中的超参数,例如历元数。
确保根据系统中数据和结果文件夹的路径编辑规格文件中的路径。
培训模型
我们提供了一个在 HMDB5 数据集上训练的预训练 RGB-only 模型。使用预训练模型,您甚至可以用更少的时间获得更好的准确性。
print("Train RGB only model with PTM")
!action_recognition train \ -e $HOST_SPECS_DIR/train_rgb_3d_finetune.yaml \ -r $HOST_RESULTS_DIR/rgb_3d_ptm \ -k $KEY \ model_config.rgb_pretrained_model_path=$HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt \ model_config.rgb_pretrained_num_classes=5
评估模型
我们提供了两种不同的样本策略来评估视频剪辑上的预训练模型。
- 中心模式: 选取序列的中间帧进行推断。例如,如果模型需要 32 帧作为输入,而视频剪辑有 128 帧,则从索引 48 到索引 79 中选择帧进行推断。
- conv mode: 从单个视频中抽取 10 个序列并进行推断。最终结果取平均值。
接下来,评估使用 PTM 培训的 RGB 模型:
!action_recognition evaluate \ -e $HOST_SPECS_DIR/evaluate_rgb.yaml \ -k $KEY \ model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt \ batch_size=1 \ test_dataset_dir=$HOST_DATA_DIR/test \ video_eval_mode=center
video_eval_mode=center
Inferences
在本节中,您将运行动作识别推理工具,以使用经过训练的 RGB 模型生成推理并打印结果。
与评估一样,推理也有两种模式:中心模式和转换模式。最终输出显示视频中的每个输入序列标签:[video_sample_path] [labels list for sequences in the video sample]
!action_recognition inference \ -e $HOST_SPECS_DIR/infer_rgb.yaml \ -k $KEY \ model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt \ inference_dataset_dir=$HOST_DATA_DIR/test/ride_bike \ video_inf_mode=center
您可以在此数据集上看到推理函数结果的示例。

结论
NVIDIA TAO 和预训练模型通过消除从头构建模型的需要,帮助您加快定制模型的开发。
借助 NGC catalog 的快速部署功能,您可以在几分钟内访问环境以构建和运行计算机视觉应用程序。这使您能够专注于开发,避免在基础架构设置上花费时间。




