
MLPerf benchmarks 由工业界、学术界和研究实验室的人工智能领导者组成的联盟开发,旨在提供标准、公平和有用的深度学习性能测量。 MLPerf 训练侧重于测量时间,以便为以下任务训练一系列常用的神经网络:
- 自然语言处理
- 语音识别
- 推荐系统
- 生物医学图像分割
- 目标检测
- 图像分类
- 强化学习
减少培训时间对于加快部署时间、最小化总体拥有成本和最大化投资回报至关重要。
然而,与平台性能一样重要的是它的多功能性。训练每个模型的能力,以及提供基础设施可替代性以运行从训练到推理的所有人工智能工作负载的能力,对于使组织能够最大限度地实现其基础设施投资的回报至关重要。
NVIDIA platform 具有全堆栈创新和丰富的开发人员和应用程序生态系统,仍然是唯一提交所有八个 MLPerf 训练测试结果,以及提交所有 MLPerf 推理和 MLPerf 高性能计算( HPC )测试结果的系统。
在本文中,您将了解 NVIDIA 在整个堆栈中部署的方法,以在 MLPerf v2.0 中提供更高的性能。
全堆栈改进
NVIDIA MLPerf v2.0 提交基于经验证的 A100 Tensor Core GPU 、 NVIDIA DGX A100 系统 以及 NVIDIA DGX SuperPOD 参考架构。许多合作伙伴还使用 A100 Tensor Core GPU 提交了结果。
通过整个堆栈(包括系统软件、库和算法)的持续创新,与之前使用相同 A100 Tensor Core GPU 提交的文件相比, NVIDIA 再次实现了性能改进。
与 NVIDIA MLPerf v0.7 提交的第一批 A100 Tensor Core GPU 提交相比,结果表明,每个芯片的增益高达 2.1 倍,最大规模训练的增益为 5.7 倍(表 1 )。
| Benchmark | v2.0 Max-Scale Time to Train (min) (vs. v1.1) (vs. v0.7) | v2.0 Per-Accelerator Time to Train (min) (vs. v1.1) (vs. v0.7) |
| Recommendation (DLRM) | 0.59 (1.08x) (5.66x) |
12.78 (A100) (1.07x) (2.08x) |
| Natural Language Processing (BERT) | 0.21 (1.10x) (4.48x) |
126.95 (A100) (1.26x) (2.69x) |
| Image Classification (ResNet-50 v1.5) | 0.32 (1.09x) (2.38x) |
217.82 (A100) (1.07x) (1.46x) |
| Speech Recognition (RNN-T) | 2.15 (1.10x) (NA*) |
230.07 (A100) (1.19x) (NA*) |
| Image Segmentation (3D U-Net) | 1.22 (1.13x) (NA*) |
170.23 (A100) (1.20x) (NA*) |
| Object Detection – Lightweight (RetinaNet) | 4.25 (NA**) (NA**) |
675.18 (A100) (NA**) (NA**) |
| Object Detection – Heavyweight (Mask R-CNN) |
3.09 (1.05x) (3.39x) |
327.34 (A100) (1.13x) (2.01x) |
| Reinforcement Learning (MiniGo) | 16.23 (0.95x) (1.05x) |
2045.37 (A100) (1.04X) (1.17x) |
MLPERF v1.1 Submission details :
每加速器: BERT : 1.1-2066 | DLRM:1.1-2064 |掩码 R-CNN:1.1-2066 | Resnet50 v1.5:1.1-2065 | RNN-T:1.1-2066 | 3D U-Net:1.1-2065 | MiniGo:1.1-2067
最大比例: BERT : 1.1-2083 | DLRM:1.1-2073 | Mask R-CNN:1.1-2076 | Resnet50 v1.5:1.1-2082 | SSD:1.1-2070 | RNN-T:1.1-2080 | 3D U-Net:1.1-2077 | MiniGo:1.1-2081 (*)
MLPERF v2.0 Submission details :
每加速器: BERT : 2.0-2070 | DLRM:2.0-2068 | Mask R-CNN:2.0-2070 | Resnet50 v1.5:2.0-2069 | RetinaNet:2.0-2091 | RNN-T:2.0-2066 | 3D U-Net:2.0-2060 | MiniGo:2.0-2059
最大比例: BERT : 2.0-2106 | DLRM:2.0-2098 | Mask R-CNN:2.0-2099 | Resnet50 v1.5:2.0-2107 | RetinaNet:2.0-2103 | RNN-T:2.0-2104 | 3D U-Net:2.0-2100 | MiniGo:2.0-2105
使用 8xA100 服务器训练时间并将其乘以 8 计算出 A100 的每加速器性能。 3D U-Net 和 RNN-T 不是 MLPerf v0.7 的一部分。(**)RetinaNet 不是 MLPerf v0.7 或 v1.1 的一部分。 MLPerf 名称和徽标是商标。有关更多信息,请参阅 www.mlperf.org.
以下各节重点介绍了为实现这些改进所做的一些工作。
BERT
最新的 NVIDIA BERT 提交利用了以下优化:
- 顺序包装
- 全连接层和 GELU 层的融合
顺序包装
在前几轮中,填充批次所需的填充相关开销已经通过引入未添加优化进行了优化。然而,取消添加会导致缓冲区大小动态变化,因为令牌总数不再固定。
当我们不必使用 CUDA 图时,例如当使用大批量时,这不是一个问题。然而,对于小批量,其中 CUDA 图用于减少 CPU 开销,动态大小的缓冲区需要针对每个可能的大小使用许多单独的图。为了有效利用 CUDA 图,同时最小化填充开销, NVIDIA 在这一轮中使用了序列打包的概念。
在来自 Transformers ( BERT )的 MLPerf 双向编码器表示中,训练样本被限制为 512 个令牌,但其令牌通常少于 512 个。由于训练序列具有不同的长度,因此可以在 512 个令牌样本中拟合多个序列。
序列压缩要求预先知道训练集序列的长度分布。序列可以合并到压缩样本中,这样合并的样本中没有一个超过 512 个令牌的长度。
NVIDIA 使用了与另一个提交者 用于 MLPerf v1.1 类似的打包算法。 GPU 具有高度的通用编程能力,因此可以采用来自不同提交方的算法。
为了在实现复杂性和性能之间取得良好的平衡,每个样本中最多包含三个序列。这导致每个训练样本包含不同数量的序列,因为一批三个样本可以包含三到九个序列。
CUDA 图要求每个图的缓冲区大小随时间固定。通过为批次中每个可能的序列数创建一个单独的图来处理不同数量的总序列。
对于大规模训练,我们使用每个芯片两个批次的大小。这转化为五到七个单独的图,这远低于开始提到的未添加优化所需的数量。
总的来说,对于 4096- GPU 和 1024- GPU 场景,该技术分别将大规模运行的结果提高了 10% 和 33% 。
全连接层和 GELU 层的融合
BERT 使用高斯误差线性单元( GELU )激活函数,该函数遵循完全连接层。在之前提交的文件中, GELU 激活函数是作为单个内核实现的。这种方法需要额外的内存事务来进行输入读取和输出写入。
在这一轮中, NVIDIA 实现了完全连接层(矩阵乘法操作)与 GELU 激活函数的融合。这消除了对大量内存读写操作的需要,使总吞吐量增加了 2-4% ——每芯片批量越大,收益越大。
通常,将激活数学融合到矩阵乘法运算的末尾更有效,这意味着将 GELU 激活函数融合到不同的完全连接层中(图 1 )。
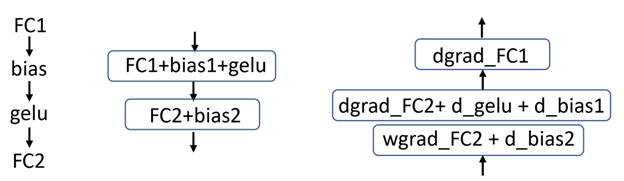
深度学习推荐模型
最新的 NVIDIA 深度学习推荐模型( DLRM )提交再次利用了 NVIDIA Merlin HugeCTR ,一个用于推荐系统的优化开源深度神经网络训练框架。
内核融合
多层感知器( MLP )是 DLRM 的关键构建块。为了减少全局内存的访问次数,元素核和通用矩阵乘法( GEMM )核的融合得到了广泛应用。
这个 NVIDIA cuBLAS 库 最近引入了一种新的融合类型: GEMM 和 DReLU (将 ReLU 梯度计算与反向过程中的矩阵乘法运算融合)。 HugeCTR 利用这种新的融合类型来提高 MLP 的性能。
改进了计算和通信的重叠
提高 GPU 利用率对于提供最高性能非常重要。
在最新提交的文件中, NVIDIA 显著改善了混合嵌入评估中计算和通信的重叠,以提高 GPU 利用率。具体来说,迭代 i 中密集网络的执行通过流水线与迭代 i + 1 中嵌入的执行重叠,增加了 GPU 的利用率。
这种重叠是可能的,因为在评估阶段没有迭代之间的依赖关系。
此外,还优化了混合嵌入的前向/后向分层all-to-all操作中的几个关键内核。
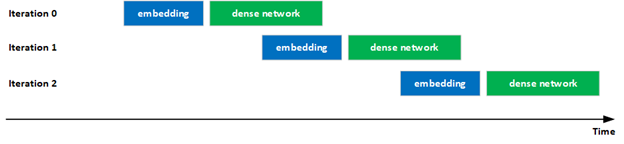
ResNet-50
对于 ResNet-50 ,我们采用了以下优化来提高性能:
- 更好的最大规模训练配置
- 更快的 cuDNN 内核
更好的最大规模训练配置
当对模型进行大规模训练时,如果全局批量大小不是数据集中训练图像的整数倍,则会在历元的最后一次迭代中添加额外数据,以使批量大小在迭代中保持一致。如果全局批大小接近数据集的整数倍,则可以避免浪费的计算。这对于大规模训练尤其重要,因为全局批量相对较大。
在这一轮 MLPerf 中,我们得出结论,使用 527 个节点,全局批量大小为 67456 ,显著减少了浪费的计算,与 MLPerf v1.1 中 NVIDIA 提交的 ResNet-50 相比,性能提升了 3.5% 。
更快的 cuDNN 内核
对于提交的 ResNet50 , NVIDIA 显著改进了 cuDNN 提取的内核。这包括针对层大小选择更好的内核,以及针对不同分片大小优化内核实现。
从这些优化的内核采样中,我们观察到 MLPerf v1.1 的大规模配置的吞吐量提高了 4% 以上。
RetinaNet
NVIDIA RetinaNet 提交利用了几种软件优化,包括:
- 通道最后存储格式和自动混合精度
- 使用融合加速
- 优化损耗块
- 异步评分
- CUDA 图
通道最后存储格式和自动混合精度
为了避免内存重组并有效提高峰值性能, NVIDIA 使用了 PyTorch 通道最后内存格式 ( NHWC 而非 NCHW )和 PyTorch 自动混合精度 (AMP).
使用融合加速
对于 RetinaNet 提交, NVIDIA took 利用了几个融合机会。通过 Apex 库的 cuDNN 运行时融合用于融合 CONV-bias-ReLU 和 CONV-bias-pattern ,而 PyTorch NVFuser 用于融合元素操作,例如 scale-bias-ReLU 和 scale-bias-add-ReLU 。
cuDNN 运行时融合 Python 接口可以在 Apex repository (从apex.contrib.conv_bias_relu导入 ConvBiasReLU 或 ConvBias )中找到。
优化损耗块
RetinaNet 损耗相关计算分为两个阶段:地面实况数据预处理和实际损耗计算。
由于地面实况数据预处理不依赖于模型输出,部分地面实况数据处理通过 custom functions 卸载到 DALI ,使其能够异步执行,提高了系统资源利用率。预处理的其余部分被重新实现,然后合并到模型图中以避免抖动。
对于损耗计算,使用了优化的焦损实现,可在 Apex library 中找到。
异步评分
RetinaNet 提交指南要求在每个训练期后进行评估(推断和评分)。由于 OpenImages 验证数据集中有大量图像和边界框,以及评分代码的顺序实现,评分时间开销很大。
为了减轻评分开销,特别是在大规模执行中,实现了异步评分,以便下一个训练历元掩盖了前一个历元评分过程。

CUDA 图
CUDA 图 在 NVIDIA RetinaNet 提交中广泛使用。绘制了整个模型和地面实况预处理的部分,这需要重新实现它们以适应 CUDA 图约束。
该模型的正向和反向过程被图形捕捉,以及地面实况预处理的部分。后者需要代码自适应以适应 CUDA 图约束。
有关更多信息,请参阅 用 CUDA 图加速 PyTorch .
掩码 R-CNN
NVIDIA Mask R-CNN 提交使用了几种技术来提高性能:
- 瓶颈块优化
- RPN 头部融合
- 评价
- Top-K
瓶颈块优化
resnet主干构建为瓶颈块堆栈,每个瓶颈块由三个连续卷积组成。每个卷积后面跟着一个批范数和一个 ReLu 。批范数模块有四个参数,在正向方法中计算两个中间项需要一些数学知识。
由于批量规范被冻结,参数永远不会更改,这意味着中间项也不会更改。为了节省时间,这些中间项只计算了一次。
ReLu 的反向传播涉及创建和应用掩码。在早期版本的代码中,该掩码以半( FP16 )精度存储。在这一轮中, DReLU 掩码表示为布尔值,而不是 FP16 ,以减少内存事务。
在反向传播过程中,为三个卷积层中的每一层计算数据梯度和权重梯度。 NVIDIA 根据经验发现,虽然数据梯度 GPU 内核使用足够数量的 CTA 来启动,以充分利用 GPU ,但权重梯度内核使用的 CTA 要少得多。
实现的一个优化是首先启动数据梯度核,然后在单独的流上启动所有三个权重梯度核,以便它们同时运行。这减少了权重梯度的总计算时间。
Apex 中的 瓶颈块模块 中的 PyTorch 用户可以使用这些优化。
RPN 头部融合
如 RetinaNet 一节所述,实现了一个新的 Apex 模块,该模块融合了卷积、偏置和 ReLu 。该模块位于 MaskR CNN 中,用于融合 RPN 头块中某些层的正向传播。
评价
平均而言,评估所需的时间几乎与培训所需的时间相同。评估在专用节点上异步完成,但结果通过阻塞广播与训练节点共享。
训练节点在开始等待评估广播之前等待一定数量的步骤,以最小化任何评估结果等待时间。学习率曲线有两个拐点,模型在通过最后一个拐点之前收敛的可能性极小。这就是为什么你应该等待尽可能长的时间来检查评估结果,直到训练通过最后一个学习率曲线拐点。
Top-K
在 PyTorch 的早期版本中, top-k 内核启动的 CTA 数量与每 GPU 批大小成比例。当批量大小等于 1 时,这产生了较差的性能,该批量大小通常用于 NVIDIA max scale 运行。
在前几轮中,我们使用两阶段 top-k 方法解决了这个问题,该方法是用 Python 实现的,但该解决方案并没有得到很好的推广。关于更普遍解决方案的工作已经在进行中。
在这一轮中, NVIDIA 与 PyTorch 团队合作,以确保新的 top-k 实现在批量为 1 的情况下产生更好的性能,并进入 PyTorch 。完成后,以前的两阶段 top-k 实现被新的 PyTorch 模块所取代。
3D U-Net
3D U-Net 具有多个大层,输入通道数为 32 。对于wgrad内核,使用默认为 64x256x64 的内核意味着显著的块大小量化损失。
由于在 cuDNN 中引入了新的 32x256x32 wgrad内核,从而节省了分片大小量化损失。这导致 MLPerf v2.0 中单个节点的加速比 MLPerf v1.1 高出 5% 以上。
RNN-T
递归神经网络传感器( RNN-T )的预处理步骤相对密集。多亏了 DALI ,大部分预处理开销可以通过管道传输并隐藏在主训练循环下。
然而,由于输入数据的大小可能不同,因此需要在初始迭代后重新定位内部内存缓冲区,从而增加预热阶段的长度。
DALI 最近已切换到基于内存池的分配器,其中池使用cuMem API 进行管理。这显著减少了分配新缓冲区的开销,在训练中产生了更快的预热过程。
结论
多亏了整个堆栈的优化, NVIDIA 平台再次能够使用经验证的 NVIDIA A100 Tensor Core GPU 和 NVIDIA DGX A100 平台提高 MLPerf Training v2.0 的性能。
NVIDIA 仍然是在 MLPerf 基准测试套件中提交结果的唯一平台,包括 MLPerf 培训、 MLPerf 推理和 MLPerf HPC 。这展示了整个平台的性能和多功能性,随着现代人工智能在每个计算领域的普及,这一点至关重要。
除了在 MLPerf 存储库中提供用于 NVIDIA MLPerf 提交的软件外,还为 NVIDIA GPU 、 在 NGC hub 上可用 制作并优化了数十个其他模型。
NVIDIA 平台也无处不在,为客户提供了运行模型的选择。 NVIDIA A100 可从所有主要服务器制造商和云服务提供商处获得,允许您在本地、云中、混合环境或边缘部署。




