
量子电路模拟对于开发量子计算机的应用程序和算法至关重要。由于已知量子计算算法和用例的破坏性,政府、企业和学术界的量子算法研究人员正在开发新的量子算法,并在更大的量子系统上进行基准测试。
在没有大规模纠错量子计算机的情况下,开发这些算法的最佳方法是通过量子电路模拟。量子电路模拟需要大量计算, GPU 是计算量子态的天然工具. 为了模拟更大的量子系统,有必要将计算分布在多个 GPU 和多个节点上,以充分利用超级计算机的计算能力。
NVIDIA cuQuantum 是一个软件开发工具包( SDK ),使用户可以使用 GPU 轻松加速和缩放量子电路模拟,为探索量子优势提供了新的能力。
此 SDK 包括最近发布的 NVIDIA DGX cuQuantum Appliance ,这是一个支持部署的软件容器,具有多 GPU 状态向量模拟支持。通用多 GPU API 现在也可在 cuStateVec 中使用,以便轻松集成到任何模拟器中。对于张量网络模拟, cuQuantum cuTensorNet library 提供的切片 API 可实现分布在多个 GPU 或多个节点上的加速张量网络收缩。这使得用户可以利用 DGX A100 系统的近线性强伸缩性。
NVIDIA cuQuantum SDK 具有状态向量和张量网络方法库。这篇文章主要关注用于多节点状态向量模拟的 cuStateVec 和 DGX cuQuantum 设备 。如果您有兴趣了解更多关于 cuTensorNet 和张量网络方法的信息,请参见 使用 NVIDIA cuTensorNet 扩大 Quantum Circuit Simulation 。
什么是多节点、多 GPU 状态矢量仿真
节点是由紧密互连的处理器组成的单个封装单元,这些处理器经过优化,可以在保持机架就绪外形的同时协同工作。多节点多 GPU 状态向量模拟利用了一个节点内的多个 GPU 和 GPU 的多个节点,以提供比其他方式更快的解决时间和更大的问题规模。
DGX 使用户能够利用高内存、低延迟和高带宽。 DGX H100 system 由八个 H100 张量芯 GPU 组成,利用了 第四代 NVLink 和第三代 NVSwitch 。该节点是量子电路模拟的发电站。
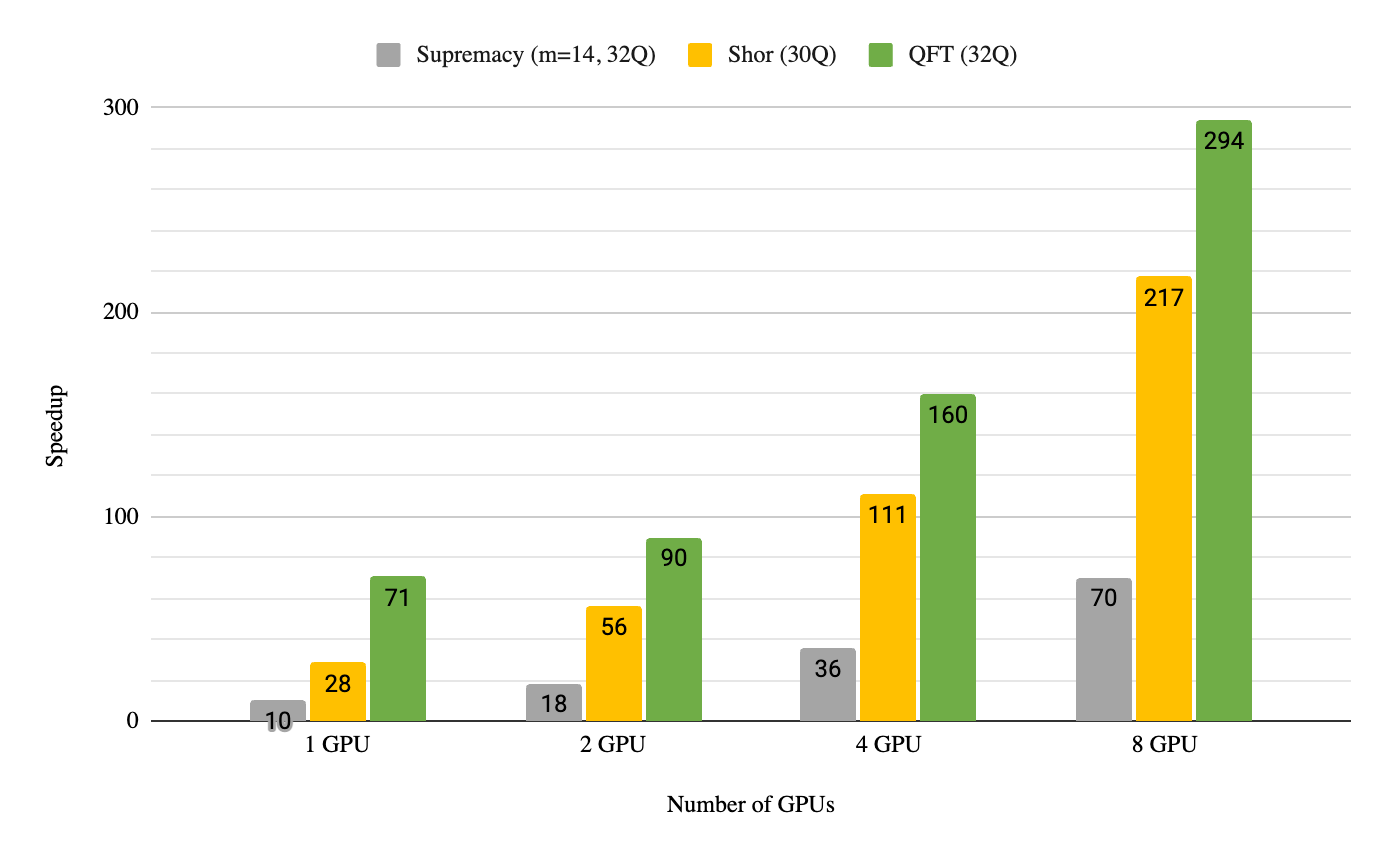
在 DGX A100 节点上运行,所有八个 GPU 上都有启用 NVIDIA 多 GPU 的 DGX cuQuantum Appliance ,对于三种常见的量子计算算法:量子傅里叶变换、肖氏算法和 Sycamore Supremacy 电路,在双 64 核 AMD EPYC 7742 处理器上的速度提高了 70 到 290 倍。这使得用户能够使用单个 DGX A100 节点(八个 GPU ),通过全状态矢量方法模拟多达 36 个量子比特。图 1 所示的结果比我们上次宣布此功能的基准测试高出 4.4 倍,这是因为我们的团队已经实现了只使用软件的增强。
NVIDIA cuStateVec 团队深入研究了除单个节点内的多个 GPU 之外,利用多个节点的性能方法。因为大多数门应用程序都是完全并行的操作,所以节点内和跨节点的 GPU 可以被编排以进行分而治之。
在模拟过程中,状态向量被分割并分布在 GPU 之间,每个 GPU 可以对其状态向量的一部分并行应用一个门。在许多情况下,这可以在本地处理;然而,高阶量子比特的门应用需要分布式状态向量之间的通信。
一种典型的方法是首先对量子比特重新排序,然后在每个 GPU 中应用门,而不访问其他 GPU 或节点。这种重新排序本身需要设备之间的数据传输。为了有效地做到这一点,高互连带宽变得极其重要。在多个节点上有效地利用这种并行性是非常重要的。
介绍多节点 DGX cuQuantum Appliance
这里给出了基于性能和任意尺度状态矢量的量子电路模拟的答案。 NVIDIA 很高兴宣布新 DGX cuQuantum Appliance 提供的多节点、多 GPU 功能。在我们的下一版本中,任何 cuQuantum 容器用户都将能够快速、轻松地利用 IBM Qiskit 前端在世界上最大的 NVIDIA 系统上模拟量子电路。
cuQuantum 的任务是使尽可能多的用户能够轻松加速和缩放量子电路模拟。为此, cuQuantum 团队正在努力将 NVIDIA 多节点方法生产成 API ,该 API 将于明年初正式上市。通过这种方法,您将能够利用更广泛的基于 NVIDIA GPU 的系统来扩展状态向量量子电路模拟。
NVIDIA 多节点 DGX cuQuantum 设备正处于开发的最后阶段,您很快就能利用 NVIDIA DGX SuperPOD 系统 的最佳性能。这将作为 NGC 托管的容器映像提供,您可以在 Docker 和几行代码的帮助下快速部署。
NVIDIA DGX H100 拥有所有 DGX 系统中最快的 I / O 架构,是大型 AI 群集(如 NVIDIA -DGX SuperPOD )的基础构建块,是可扩展 AI 的企业蓝图,现在是量子电路仿真基础设施。 DGX H100 中的八台 NVIDIA H100 GPU 使用新的高性能第四代 NVLink 技术,通过四台第三代 NVSwitch 进行互连。
第四代 NVLink 技术提供了上一代 1.5 倍的通信带宽,比 PCIe Gen5 快 7 倍。它提供了高达 7.2 TB / s 的 GPU 总吞吐量至 – GPU ,比上一代 DGX A100 提高了近 1.5 倍。
DGX H100 系统与随附的八个 NVIDIA ConnectX-7 InfiniBand / Ethernet 适配器(每个适配器都以 400 GB / s 的速度运行)一起,提供了强大的高速结构,可在分布于多个节点的状态矢量之间的全局通信中节省开销。多节点、多 GPU cuQuantum 与大规模 GPU 加速计算相结合,利用最先进的网络硬件和软件优化,这意味着 DGX H100 系统可以扩展到数百或数千个节点,以应对最大的挑战,例如将全状态矢量量子电路模拟扩展到 50 个量子比特以上。
为了对这项工作进行基准测试,多节点 DGX cuQuantum Appliance 运行在 NVIDIA Selene Supercomputer 上,这是 NVIDIA DGX SuperPOD 系统的参考体系结构。截至 2022 年 6 月, Selene 在超级计算系统 TOP500 榜单中排名第八 ,以 63.5 petaflops 的速度执行高性能 Linpack ( HPL )基准测试,并以 24.0 giaflops /瓦特的速度在 Green500 名单上排名第 22 。
NVIDIA 利用多节点 DGX cuQuantum Appliance 运行基准测试: Quantum Volume 、 Quantum 近似优化算法( QAOA )和 Quantum 相位估计。量子体积电路的深度为 10 和 30 。 QAOA 是一种常用算法,用于解决相对而言近期量子计算机上的组合优化问题。我们用两个参数运行它。
在前面的算法中演示了弱标度和强标度。很明显,扩展到像 NVIDIA DGX SuperPOD 这样的超级计算机对于加快解决时间和扩展相空间研究人员可以利用状态矢量量子电路模拟技术探索的相空间都很有价值。
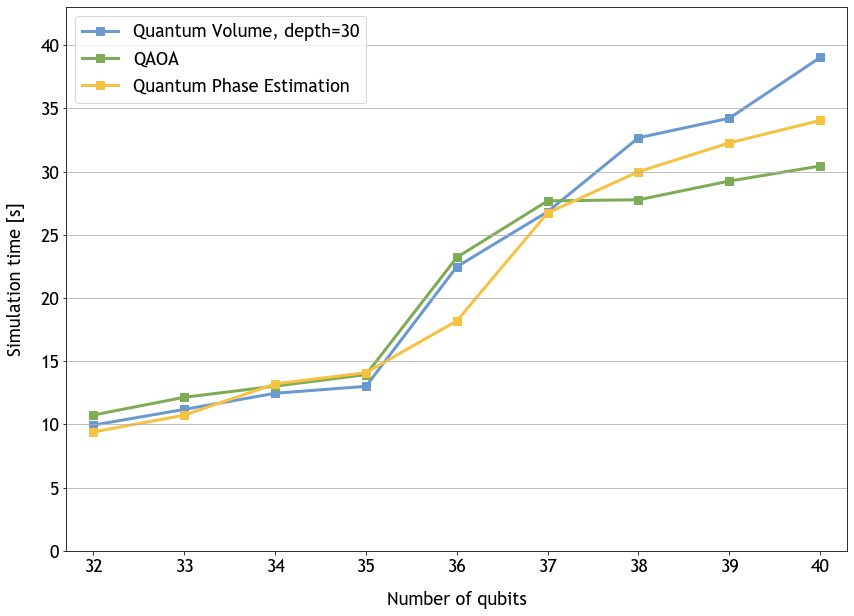
我们正在通过更新的 DGX cuQuantum Appliance 进一步帮助用户实现规模化。通过引入多节点功能,我们允许用户在一个 GPU 上移动 32 个量子比特,在一个 NVIDIA 安培架构节点上移动 36 个量子比特。我们用 32 个 DGX A100 节点模拟了总共 40 个量子比特。用户现在可以根据系统配置进一步扩展,软件限制为 56 量子位或数百万 DGX A100 节点。我们在 NVIDIA Hopper GPU 上的其他初步测试表明,这些数字在我们的下一代架构上会更好。
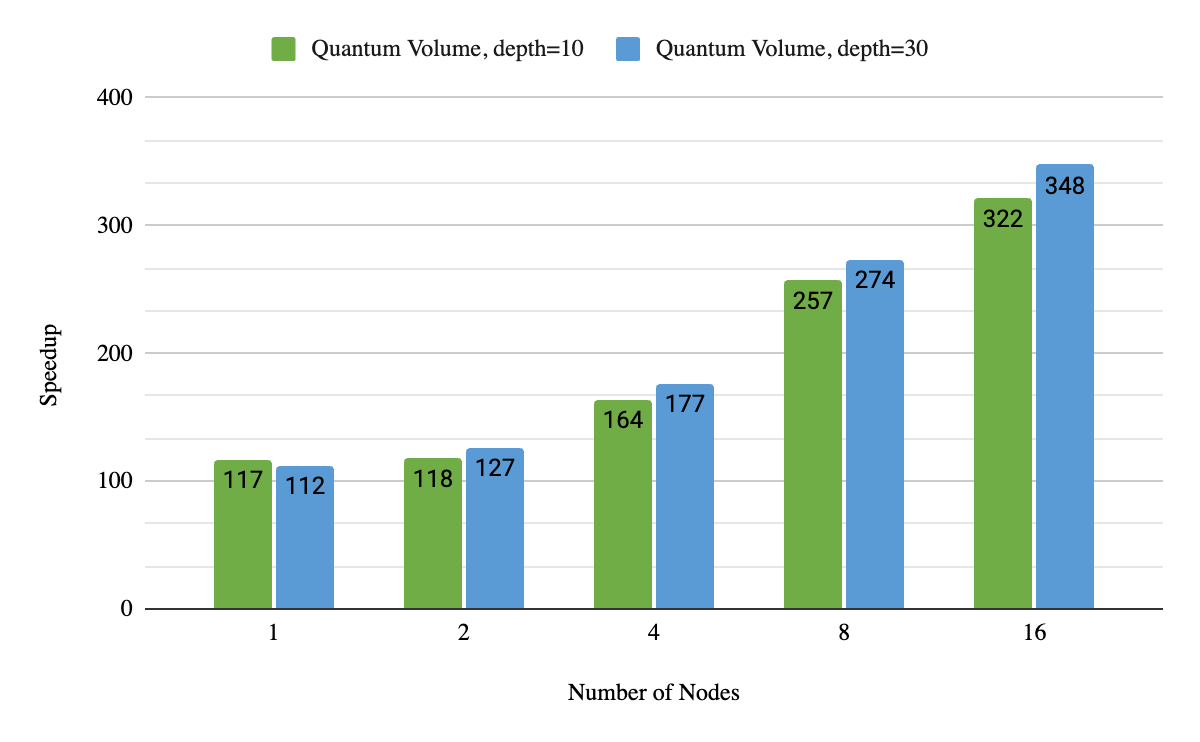
我们还衡量了我们多节点能力的强大扩展性。为了简单起见,我们专注于 Quantum Volume 。图 3 描述了当我们多次改变 GPU 的数量来解决同一问题时的性能。与最先进的双插槽服务器 CPU 相比,在利用 16 个 DGX A100 节点时,我们获得了 320 到 340 倍的加速。这也比以前最先进的量子体积实现快 3.5 倍(对于只有两个 DGX A100 节点的 36 个量子比特,深度= 10 )。当添加更多节点时,这种加速会变得更加显著。
在最大的 NVIDIA 系统上模拟和缩放量子电路
NVIDIA 的 cuQuantum 团队正在将状态向量模拟扩展到多节点、多 GPU 。这使得终端用户能够对比以往任何时候都大的全状态矢量进行量子电路模拟。 cuQuantum 不仅支持扩展,还支持性能,显示节点之间的扩展能力较弱,扩展能力较强。
此外, cuQuantum 推出了第一个由 cuQuantom 支持的 IBM Qiskit 映像。在我们的下一个版本中,您将能够拉动这个容器,从而使用这个流行的框架更容易、更快地扩展量子电路模拟。
虽然多节点 DGX cuQuantum Appliance 今天处于私人测试阶段,但 NVIDIA 预计将在未来几个月公开发布。 cuQuantum 团队打算在 2023 年春季发布 cuStateVec 库中的多节点 API 。
DGX cuQuantum 应用 入门
当多节点 DGX cuQuantum 应用 在今年晚些时候正式上市时,您将能够从 NGC catalog for containers 中提取 Docker 映像。
您可以通过 Quantum Computing Forum 向 cuQuantum 团队提出问题。 有关 NVIDIA/cuQuantum GitHub 回购的功能请求或报告错误,请联系我们。
有关详细信息,请参阅以下资源:
- cuQuantum (includes cuTensorNet)
- cuQuantum documentation
- NVIDIA/cuQuantum GitHub repo
- DGX cuQuantum Appliance
- What Is Quantum Computing?
- Lightning Fast simulations with Pennylane and the NVIDIA cuQuantum SDK
- Orquestra Integration with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
GTC 2022 和 cuQuantum
加入我们的 GTC 2022 课程,了解更多有关 NVIDIA cuQuantum 和其他进步的信息:
- GTC 2022 Keynote
- A Deep Dive into the Latest HPC Software
- Defining the Quantum-Accelerated Supercomputer
- Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
- Quantum Computing Simulation in Pharmaceuticals Research
- Accelerating Quantum Computing Research with GPUs
- AI for Science: Heralding Scientific Breakthroughs through AI




