随着音频和视频流、会议和电信的兴起,开发人员必须构建具有卓越音频质量的应用程序,并使最终用户能够有效地进行通信和协作。各种背景噪音会干扰通信,从交通和建筑到狗吠和婴儿哭闹。此外,用户可以在放大回声的大房间里讲话。
NVIDIA Maxine提供了一种易于使用的 Audio Effects SDK 和 AI 神经网络音频质量增强算法,以解决虚拟协作和内容创建应用程序中音频质量差的问题。使用 Audio Effects SDK ,您可以消除几乎任何类型的噪音,包括房间回音,并构建能够轻松理解对话和高效会议的应用程序。
在本文中,您将学习如何在 Linux 或 Windows 平台上的 SDK 上使用容器构建高音频质量的应用程序。所有这些都通过预构建的示例应用程序进行了演示。
构建没有背景噪音或房间回声的应用程序
Maxine Audio Effects SDK 使您能够将窄带、宽带和超宽带音频的噪音消除和房间回声消除功能集成到应用程序中。
噪声消除
随着我们开始更多地在家工作,在我们通话的背景中有许多潜在的噪声源,例如按键声或空调压缩机的声音。我们周围的分心成为我们周围环境的一部分,比如关上门、搬家具或吸尘器。
使用噪声消除效果,您可以从音频流中去除不同的噪声,同时保留说话人声音的情感方面。例如,当最终用户感到兴奋,并在空调的背景下以更高的音调提出新想法时,噪音消除只保留说话人的声音。
房间回音消除
当一个人在一个封闭的房间里讲话时,声音会从周围的所有表面反弹。声音在多次迭代中被吸收、减弱或继续反射的程度取决于曲面的大小、几何体和材质。这种持续的声波反射会随着时间的推移而增强,并引起混响。
回声在具有更多反射表面的大房间(如混凝土墙或石墙)中更为明显。例如,想象一下高天花板大教堂中的声音混响。这种reverberant语音不适合于广泛使用的语音编码方法,如线性预测编码或码激励线性预测。混响语音的编码会导致严重的失真,在极端情况下会导致语音无法理解。
在发送语音记录之前,必须消除语音记录中的此类混响。在编码前无法消除回声的情况下,在通过扬声器将解码语音呈现给听众之前,必须尽可能多地消除回声。当用户在混响环境中讲话时,房间回音消除效果消除了语音中不必要的回声。此外,此功能支持宽带和超宽带信号。
您可以将噪音消除和房间回声消除功能结合起来,以在两个方向上获得更好的端到端音频质量。
获取适用于 Windows 或 Linux 的 Maxine Audio Effects SDK
将容器与 Kubernetes 一起使用提供了一种健壮且易于扩展的部署策略。除了预先打包的容器外,我们还提供适用于 Windows 和 Linux 平台的 Maxine Audio Effects SDK 。使用容器的好处是由于更快的部署和更短的维护时间而实现了高可扩展性、时间和成本节约。此外,由于容器的预包装性质,您不必担心容器内的特定安装。
在本文中,我们将重点介绍如何使用 Audio Effects SDK 容器。继续安装之前,请确保满足所有硬件要求。
如果您对 NVIDIA TensorRT 和 cuDNN 有丰富的经验,并且希望在裸机 Linux 系统上部署 Audio Effects SDK ,请在 Maxine 开始页面上下载特定平台的 SDK 。
音频效果 SDK Docker 容器
在容器上安装和利用高性能 Audio Effects SDK 及其最先进的 AI 模型需要四个步骤:
- 下载 NVIDIA 驱动程序
- 下载 Docker 和 NVIDIA -Docker用于将 GPU 暴露在容器中
- 使用NGC API 密钥登录 NGC 注册表
- 拉动音频效果 SDK 容器
您需要访问 NVIDIA Turing、 NVIDIA Volta 或 NVIDIA Ampere Architecture 生成数据中心 GPU s : T4 、 V100 、 A100 、 A10 或 A30 。
在 Windows 上安装 Audio Effects SDK
在 Windows 上安装 SDK 是一个简单的过程:
- 下载适用于 Windows 的 NVIDIA 图形驱动程序
- 下载 Microsoft Visual Studio 2017 或更高版本(确保安装构建工具)
- 从Maxine 开始了页面下载最新的 Audio Effects SDK 软件包
您必须拥有 NVIDIA RTX 卡才能从 Windows 上 Audio Effects SDK 的加速吞吐量和缩短延迟中获益。要在数据中心卡(如 A100 )上运行此 SDK ,请使用 Linux 包。
将 Audio Effects SDK 与预构建的示例应用程序一起使用
Audio Effects SDK 附带预构建的effects_demo和effects_delayed_streams_demo示例应用程序,以演示如何使用 SDK 。您还可以构建自己的示例应用程序。在本文中,我们将重点介绍如何运行effects_demo示例应用程序。
实时音频效果演示
effects_demo应用程序演示如何使用 SDK 将效果应用于音频。它可以用于应用噪音消除、房间回声消除或两者的组合效果来输入音频文件并将输出写入文件。
要运行此应用程序,请导航到samples/effects_demo目录,并使用以下脚本之一运行该应用程序:
$ ./run_effect.sh -a turing -s 16 -b 1 -e denoiser $ ./run_effect.sh -a turing -s 48 -b 1 -e dereverb $ ./run_effect.sh -a turing -s 16 -b 400 -e denoiser $ ./run_effect.sh -a turing -s 48 -b 400 -e dereverb_denoiser
run_effect.sh bash 脚本接受以下参数:
-a:架构可以是 NVIDIA 图灵、 NVIDIA 沃尔塔、 A100 或 A10 ,具体取决于您的 GPU 。-s:使用 48 / 16 KHz 的采样率。-b:批量大小。-e:要运行的效果:denoiser( NR )
dereverb( RER )
dereverb_denoiser(合并)
您还可以通过如下方式传递配置文件来执行effects_demo二进制文件:
# For running denoiser on NVIDIA Turing GPU with 48kHz input and batch size 1 $ ./effects_demo -c turing_denoise48k_1_cfg.txt
此配置文件应包含以下参数:
effect <denoiser/dereverb/dereverb_denoiser>sample_rate <48000/16000>model <*.trtpkg>:模型可在容器内的/usr/local/AudioFX/models目录中找到。real_time <0/1>:模拟来自物理设备或流的音频接收。intensity_ratio <0.0-1.0>:指定去噪强度比。input_wav_listoutput_wav_list
运行effects_demo示例应用程序后,已去噪的输出文件与可执行文件位于同一目录中。
延迟流上的音频效果 SDK 演示
effects_delayed_streams_demo应用程序演示如何处理延迟流。在电信领域,如果用户的音频 MIG ht 不能实时到达服务器,我们建议延迟应用去噪效果。在此示例应用程序中,每个输入流都属于以下类别之一:
one_step_delay_streams:这些流的延迟为一帧。例如,如果帧大小为 5ms ,则这些流具有 5ms 的延迟。two_step_delay_streams:这些流有两帧的延迟。例如,如果帧大小为 5ms ,则这些流具有 10ms 的延迟。always_active_streams:这些流没有延迟,始终处于活动状态。
要运行此应用程序,请导航到samples/effects_delayed_streams_demo目录并按如下方式执行二进制文件:
$ ./effects_delayed_streams_demo -c config-file
这里,-c config-file是配置文件的路径,例如,turing_denoise48k_10_cfg.txt。配置文件接受以下参数:
effect <denoiser/dereverb/dereverb_denoiser>frame_size:一个无符号整数,指定音频效果的每个音频流每帧的采样数。sample_rate <48000/16000>model <*.trtpkg>:模型可在容器内的/usr/local/AudioFX/models目录中找到。one_step_delay_streams:指定属于one_step_delay_streams类别的流标识符。two_step_delay_streams:指定属于two_step_delay_streams类别的流标识符。input_wav_listoutput_wav_list
运行effects_delayed_streams_demo示例应用程序后,已去噪的输出文件与可执行文件位于同一目录中。
使用 API 运行音频效果功能
示例应用程序使用易于使用的 Audio Effects SDK API 来运行效果。它们利用了显著的性能优势并控制了低级别 API 的批处理。在 Maxine 中创建和运行音频效果是一个简单的三步过程(图 1 )。
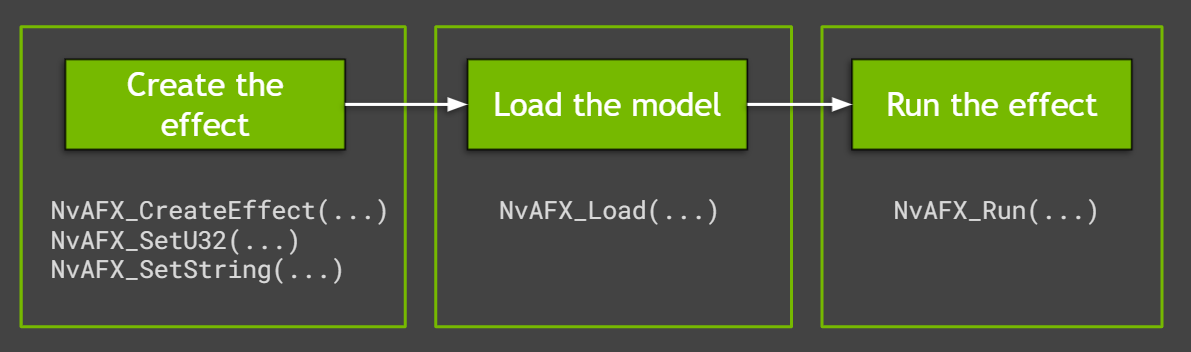
创造效果
要为噪声消除或房间回声消除创建效果,请调用NvAFX_CreateEffect函数,该函数接受带有所需参数的句柄。此函数用于在创建所需效果后返回状态代码。继续之前,请使用此状态代码检查是否有任何错误。
// Create and handle NvAFX_Handle handle; // Call CreateEffect function and pass any one of the desired effects: // NVAFX_EFFECT_DENOISER, NVAFX_EFFECT_DEREVERB, // NVAFX_EFFECT_DEREVERB_DENOISER NvAFX_Status err = NvAFX_CreateEffect(NVAFX_EFFECT_DENOISER, &handle);
每个提供的型号都支持特定的音频采样率,可以通过调用NvAFX_SetU32来指定。采样率值应为无符号 32 位整数值( 48000 / 16000 )。此外,应使用NvAFX_SetString API 调用传递所用 GPU 平台的正确模型路径,如下所示:
// Pass parameter selector NVAFX_PARAM_SAMPLE_RATE and unsigned int // Pass parameter selector NVAFX_PARAM_MODEL_PATH and character string NvAFX_Status err; err = NvAFX_SetU32(handle, NVAFX_PARAM_SAMPLE_RATE, sample_rate); err = NvAFX_SetString(handle, NVAFX_PARAM_MODEL_PATH, model_file.c_str());
由于为每个效果预设了 I / O 音频通道数和每帧采样数,因此必须将这些参数传递给效果功能。要获取支持的值列表,请调用NvAFX_GetU32函数,该函数返回预设值列表。
// Pass the selector string to get specific information like: // NVAFX_PARAM_NUM_SAMPLES_PER_FRAME, // NVAFX_PARAM_NUM_CHANNELS, unsigned num_samples_per_frame, num_channels; NvAFX_Status err; err = NvAFX_GetU32(handle, NVAFX_PARAM_NUM_SAMPLES_PER_FRAME, &num_samples_per_frame); err = NvAFX_GetU32(handle, NVAFX_PARAM_NUM_CHANNELS, &num_channels);
要在 GPU 上运行效果,必须使用NvAFX_GetSupportedDevices函数获取支持的设备列表,该函数获取支持的 GPU 数量。
// The function fills the array with the CUDA device indices of devices // that are supported by the model, in descending order of preference, // where the first device is the most preferred device. int numSupportedDevices = 0; NvAFX_GetSupportedDevices(handle, &numSupportedDevices, nullptr); std::vector<int> ret(num); NvAFX_GetSupportedDevices(handle, &numSupportedDevices, ret.data());
然后,您可以通过传递正确的 GPU 设备编号来设置要使用的 GPU 设备,如下所示:
NvAFX_SetU32(handle, NVAFX_PARAM_USE_DEFAULT_GPU, use_default_gpu_)
加载音频效果
创建效果后,必须使用NvAFX_Load函数加载模型。加载效果选择并加载模型,并验证为效果设置的参数。此函数将模型加载到 GPU 内存中,并使其为推断做好准备。要加载音频效果,请调用NvAFX_Load函数并指定创建的效果句柄。
NvAFX_Status err = NvAFX_Load(handle);
运行音频效果
最后,运行加载的音频效果,将所需效果应用于输入数据。运行效果后,读取输入内存缓冲区的内容,应用音频效果,并将输出写入输出内存缓冲区。调用NvAFX_Run函数在输入缓冲区上运行加载的音频效果。
// Pass the effect handle, input, and output memory buffer, and the parameters of the effect NvAFX_Status err = NvAFX_Run(handle, input, output, num_samples,num_channels);
音频效果应用于输入内存缓冲区且不再需要后,通过传递效果句柄,使用NvAFX_DestroyEffect(handle)函数调用清理资源。
NvAFX_Status err = NvAFX_DestroyEffect(handle);
总结
现在,我们已经了解了 Maxine Audio Effects 功能的详细信息,向您展示了如何使用适当的参数运行示例应用程序,并了解了易于使用的高性能 API ,您可以开始使用Maxine 容器或在 Windows和Linux 上将这些惊人的 AI 音频功能集成到您的应用程序中。
有关更多信息,请参阅 Maxine 开始页面。让我们知道你的想法或如果您有任何问题。