
单细胞测量技术发展迅速,彻底改变了生命科学。我们已经从测量几十个细胞扩展到数百万个细胞,从一种模式扩展到多个高维模式。单个细胞水平上的大量信息为训练机器学习模型提供了一个很好的机会,帮助我们更好地理解 intrinsic link of cell modalities ,这可能会对合成生物学和 drug target discovery 产生变革。
这篇文章介绍了模态预测,并解释了我们如何用基于 NVIDIA GPU 的 RAPIDS cuML 实现取代基于 CPU 的 TSVD 和内核岭回归( KRR ),从而加速了 NeurIPS Single-Cell Multi-Modality Prediction Challenge 的获胜解决方案。
使用 cuML ,只修改了六行代码,我们加速了基于 scikit 学习的获胜解决方案,将训练时间从 69 分钟缩短到 40 秒:速度提高了 103.5 倍!即使与 PyTorch 中开发的复杂深度学习模型相比,我们观察到 cuML 解决方案对于这种预测挑战来说更快更准确。
单细胞模态预测的挑战
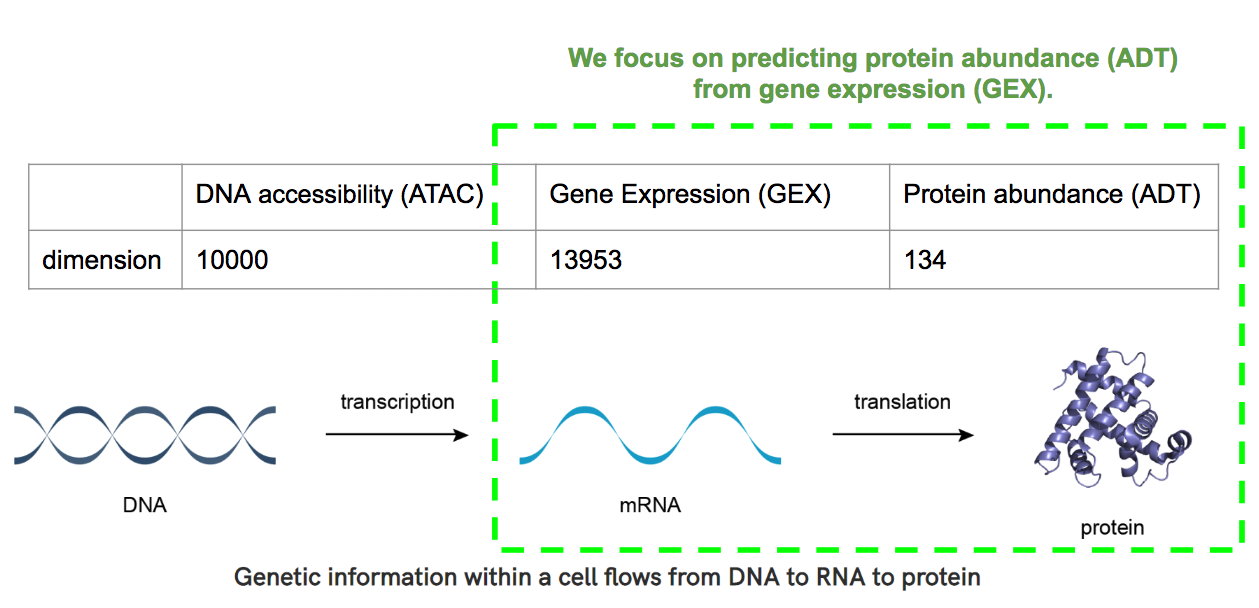
多亏了单细胞技术,我们可以测量同一单细胞内的多种形态,如 DNA 可达性( ATAC )、 mRNA 基因表达( GEX )和蛋白质丰度( ADT )。图 1 显示了这些模式之间的内在联系。只有可获得的 DNA 才能产生 mRNA ,而 mRNA 又被用作生产蛋白质的模板。
当期望从一个模态预测另一个模态时,模态预测的问题自然出现。在 2021 NeurIPS challenge 中,我们被要求预测从 ATAC 到 GEX 以及从 GEX 到 ADT 的信息流。
若一个机器学习模型能够做出好的预测,那个么它一定已经了解了细胞的复杂状态,它可以为细胞生物学提供更深入的见解。扩展我们对这些调控过程的理解,对于药物靶点的发现也具有革命性意义。
模态预测是一个多输出回归问题,它提出了独特的挑战:
- High cardinality. 例如, GEX 和 ADT 信息分别以长度为 13953 和 134 的矢量描述。
- Strong bias. 数据收集自 10 个不同的捐赠者和 4 个地点。培训和测试数据来自不同的站点。捐赠者和站点都强烈影响数据的分布。
- 稀疏、冗余和非线性。 模态数据稀疏,列高度相关。
在这篇文章中,我们专注于 GEX 到 ADT 预测的任务,以证明单个 – GPU 解决方案的效率。我们的方法可以扩展到使用多节点多 GPU 架构的具有更大数据量和更高基数的其他单细胞模态预测任务。
使用 TSVD 和 KRR 算法进行多目标回归
作为基线,我们使用了密歇根大学邓凯文教授的 NeurIPS 模态预测挑战“ GEX 到 ADT ”的 first-place solution 。核心模型的工作流程如图 2 所示。训练数据包括 GEX 和 ADT 信息,而测试数据只有 GEX 信息。
任务是预测给定 GEX 的测试数据的 ADT 。为了解决数据的稀疏性和冗余性,我们应用截断奇异值分解( TSVD )来降低 GEX 和 ADT 的维数。
特别是,两种 TSVD 模型分别适用于 GEX 和 ADT :
- 对于 GEX , TSVD 适合训练和测试的级联数据。
- 对于 ADT , TSVD 仅适合训练数据。
在邓的解决方案中, GEX 的维度从 13953 大幅降低到 300 , ADT 从 134 大幅降低到 70 。
主成分 300 和 70 的数量是通过交叉验证和调整获得的模型的超参数。然后将训练数据的 GEX 和 ADT 的简化版本与 RBF 核一起馈送到 KRR 中。根据邓的方法,在推理时,我们使用经过训练的 KRR 模型执行以下任务:
- 预测测试数据的 ADT 的简化版本。
- 应用 TSVD 的逆变换。
- 恢复测试数据的 ADT 预测。
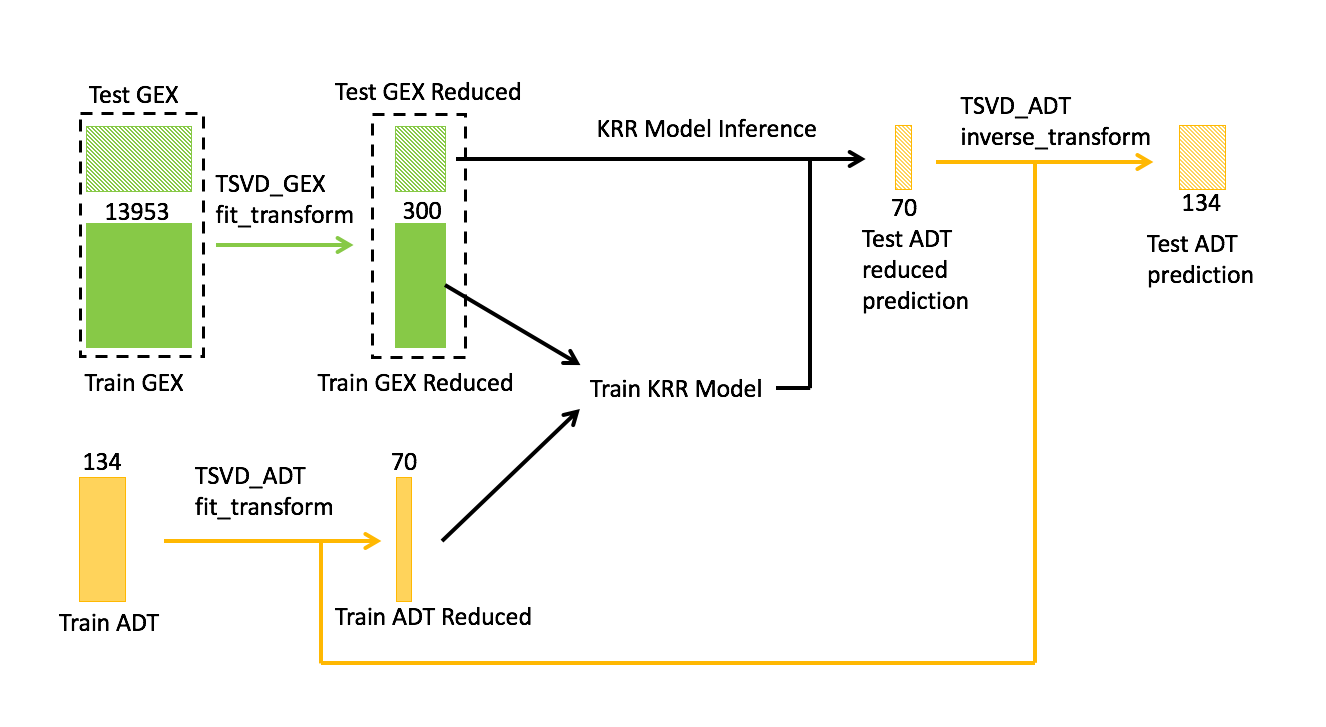
通常, TSVD 是对稀疏数据执行降维的最常用选择,通常在特征工程期间使用。在这种情况下, TSVD 用于减少特征( GEX )和目标( ADT )的尺寸。目标的降维使下游多输出回归模型更加容易,因为 TSVD 输出在列之间更加独立。
选择 KRR 作为多输出回归模型。与 SVM 相比, KRR 同时计算输出的所有列,而 SVM 一次预测一列,因此 KRR 可以像 SVM 一样学习非线性,但速度更快。
使用 cuML 实现 GPU 加速解决方案
cuML 是 RAPIDS 库之一。它包含一套 GPU 加速机器学习算法,可提供许多高度优化的模型,包括 TSVD 和 KRR 。您可以将基线模型从 scikit 学习实现快速调整为 cuML 实现。
I在下面的代码示例中,我们只需要更改六行代码,其中三行是导入。为简单起见,省略了许多预处理和实用程序代码。
Baseline sklearn implementation:
from sklearn.decomposition import TruncatedSVD
from sklearn.gaussian_process.kernels import RBF
from sklearn.kernel_ridge import KernelRidge
tsvd_gex = TruncatedSVD(n_components=300)
tsvd_adt = TruncatedSVD(n_components=70)
gex_train_test = tsvd_gex.fit_transform(gex_train_test)
gex_train, gex_test = split(get_train_test)
adt_train = tsvd_adt.fit_transform(adt_train)
adt_comp = tsvd_adt.components_
y_pred = 0
for seed in seeds:
gex_tr,_,adt_tr,_=train_test_split(gex_train,
adt_train,
train_size=0.5,
random_state=seed)
kernel = RBF(length_scale = scale)
krr = KernelRidge(alpha=alpha, kernel=kernel)
krr.fit(gex_tr, adt_tr)
y_pred += (krr.predict(gex_test) @ adt_comp)
y_pred /= len(seeds)
RAPIDS cuML implementation:
from cuml.decomposition import TruncatedSVD
from cuml.kernel_ridge import KernelRidge
import gc
tsvd_gex = TruncatedSVD(n_components=300)
tsvd_adt = TruncatedSVD(n_components=70)
gex_train_test = tsvd_gex.fit_transform(gex_train_test)
gex_train, gex_test = split(get_train_test)
adt_train = tsvd_adt.fit_transform(adt_train)
adt_comp = tsvd_adt.components_.to_output('cupy')
y_pred = 0
for seed in seeds:
gex_tr,_,adt_tr,_=train_test_split(gex_train,
adt_train,
train_size=0.5,
random_state=seed)
krr = KernelRidge(alpha=alpha,kernel='rbf')
krr.fit(gex_tr, adt_tr)
gc.collect()
y_pred += (krr.predict(gex_test) @ adt_comp)
y_pred /= len(seeds)
cuML 内核的语法与 scikit learn 略有不同。我们没有创建独立的内核对象,而是在 KernelRidge 的构造函数中指定了内核类型。这是因为 cuML 还不支持高斯过程。
另一个区别是当前版本的 cuML 实现需要显式垃圾收集。在这个特定的循环中创建了某种形式的引用循环,并且在没有垃圾收集的情况下不会自动释放对象。有关更多信息,请参阅 /daxiongshu/rapids_nips_blog GitHub 存储库中的完整笔记本。
后果
我们将 TSVD + KRR 的 cuML 实施与 CPU 基线和挑战中的其他顶级解决方案进行了比较。 GPU 解决方案在单个 V100 GPU 上运行, CPU 解决方案在双 20 核 Intel Xeon CPU 上运行。竞争的度量是均方根误差( RMSE )。
我们发现, TSVD + KRR 的 cuML 实现比 CPU 基线快 103 倍,由于管道中的随机性,分数略有下降。然而,比分仍然比比赛中的任何其他车型都好。
我们还将我们的解决方案与两种深度学习模型进行了比较:
- 第四名解决方案: Multilayer Perceptron (MLP)
- 第二名解决方案: Graph Neural Network (GNN)
这两个深度学习模型都在 PyTorch 中实现,并在单个 V100 GPU 上运行。这两个深度学习模型都有许多层,需要训练数百万个参数,因此容易对该数据集进行过度拟合。相比之下, TSVD + KRR 只需训练少于 30K 的参数。图 4 显示,由于其简单性, cuML TSVD + KRR 模型比深度学习模型更快、更准确。
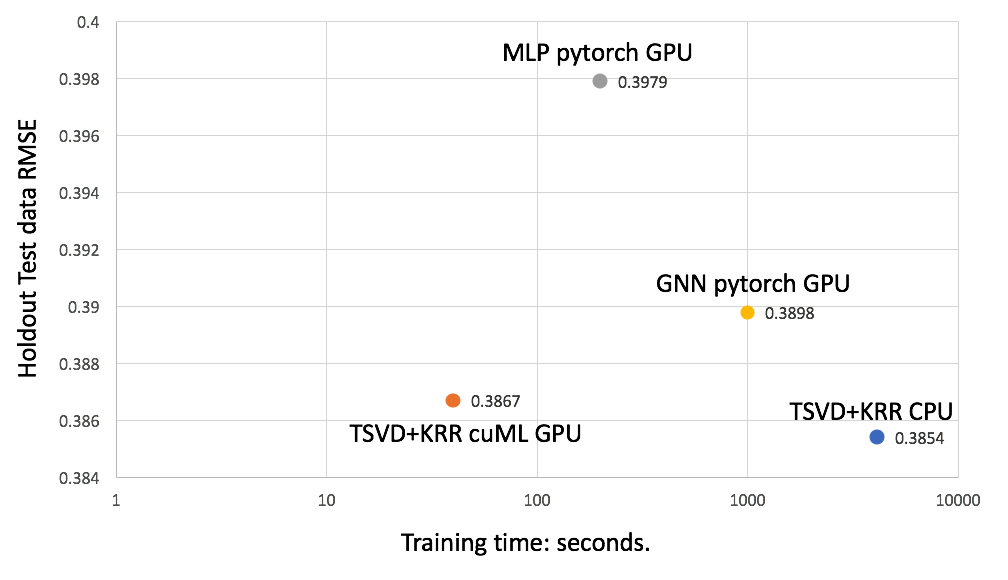
图 5 显示了一个详细的加速分析,其中我们给出了算法的两个阶段的时序: TSVD 和 KRR 。 cuML TSVD 和 KRR 分别比 CPU 基线快 15 倍和 103 倍。
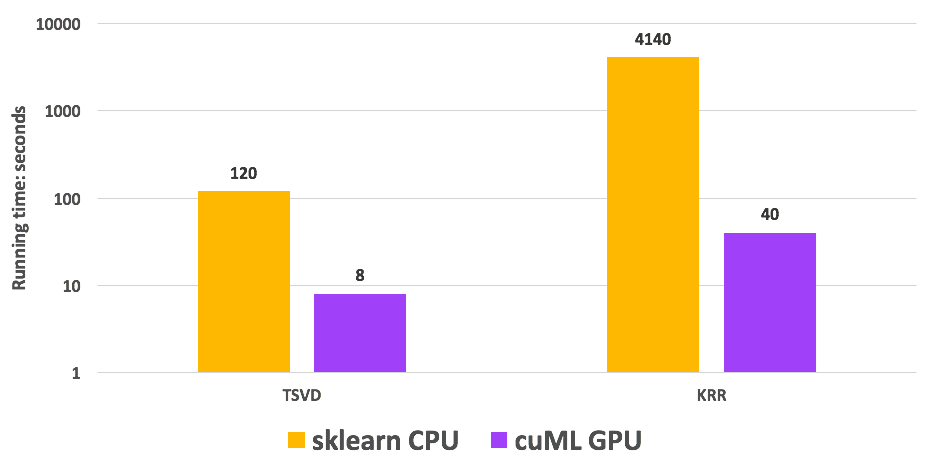
图 5.运行时比较
结论
由于其闪电般的速度和用户友好的 API , RAPIDS cuML 对于加速单细胞数据的分析非常有用。通过少量的代码更改,您可以提升现有的 scikit 学习工作流。
此外,在处理单细胞模态预测时,我们建议从 cuML TSVD 开始,以减少下游任务的数据维度和 KRR ,从而实现最佳加速。
使用 /daxiongshu/rapids_nips_blog GitHub 存储库上的代码尝试这个 RAPIDS cuML 实现。




