加载时长。它们是任何试图构建无缝体验的开发人员的祸根。在游戏中试图通过迫使玩家在狭窄的通道中摇摆或乘坐极慢的电梯来隐藏负载,会破坏沉浸感。
现在,开发人员有了更好的解决方案。 NVIDIA 与 Microsoft 和 IHV 合作伙伴合作,为 DirectStorage 1.1 开发了 GDeflate ,这是 GPU 压缩的开放标准。当前的 Game Ready Driver (版本 526.47 )包含 NVIDIA RTX IO 技术,包括对 GDeflate 的优化。
GDeflate :开放式 GPU 压缩标准
GDeflate 是一种高性能、可扩展、 GPU 优化的数据压缩方案,可以帮助应用程序利用现代 NVMe 设备上的大量数据吞吐量。它通过消除整个 I / O 管道中的 CPU 瓶颈,使此类设备的流解压缩变得切实可行。 GDeflate 还提供带宽放大效果,进一步提高 I / O 子系统的有效吞吐量。
GDeflate 开源将在 GitHub 上发布,并为 IHV 和 ISV 提供许可证。我们希望鼓励快速采用 GDeflate 作为数据并行压缩标准,促进其在 PC 生态系统和其他平台上的应用。
为了显示 GDeflate 的好处,我们在一个代表性的游戏数据集上测量了系统性能,该数据集包含纹理和几何数据,在没有压缩的情况下,使用标准 CPU 侧解压缩,以及使用 GPU 加速的 GDeflate 解压缩。
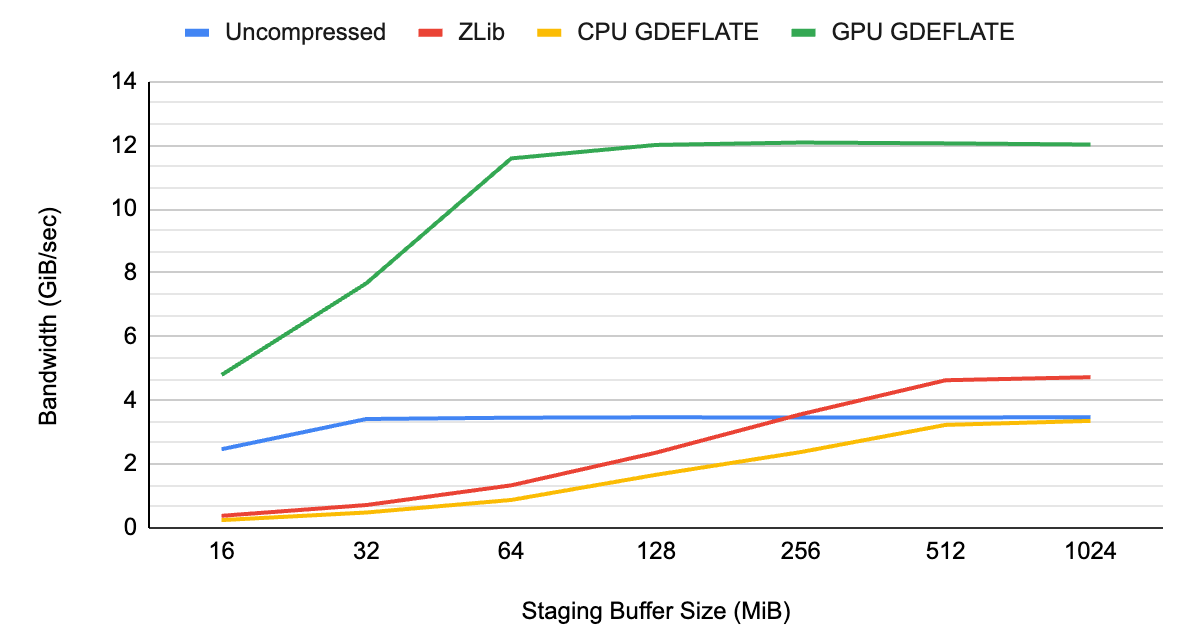
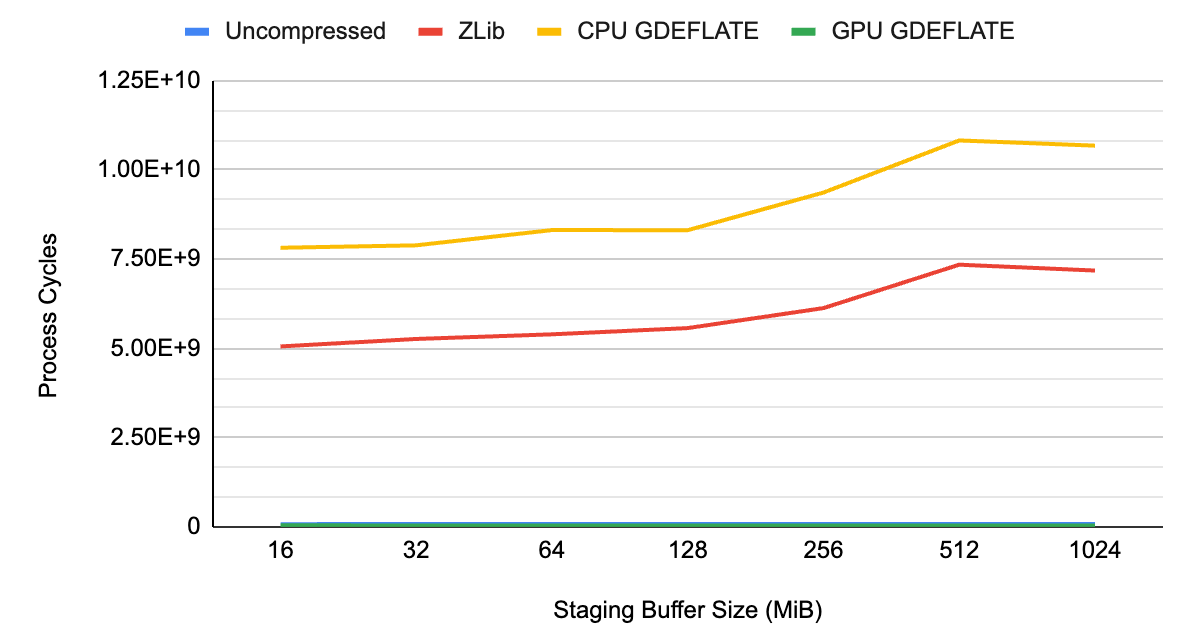
如图 1 和图 2 所示,未压缩流的数据吞吐量受到系统总线带宽的限制,大约为~ 3 GB / s ,这恰好是 Gen3 PCIe 互连的限制。
当在 CPU 上应用传统压缩和解压缩时, CPU 会成为整体瓶颈,导致吞吐量低于未压缩流的吞吐量。它不仅没有充分利用系统的可用 I / O 资源,而且还占用了其他需要 CPU 资源的任务的 CPU 周期。
通过 GPU 加速的 GDeflate 解压缩,系统可以在不应用压缩的情况下提供超出可能范围的有效带宽。它有效地将数据吞吐量乘以压缩比。 CPU 仍然完全可用于执行其他重要任务,最大限度地提高系统级性能。
GDeflate 在 DirectStorage 1.1 中作为标准 GPU 解压缩选项提供, DirectStorage 1.1 是一个来自 Microsoft 的现代 I / O 流 API 。我们期待着下一代游戏引擎通过大幅减少加载时间而从 GDeflate 中受益。
资源流和数据压缩
如今的视频游戏具有极其详细的交互环境,需要管理巨大的资产。这些数据必须首先传送到最终用户的系统,然后在运行时主动流式传输到 GPU 进行处理。游戏内容包的大部分由自然针对 GPU 的资源组成:纹理、材质和几何数据。
传统的数据压缩技术适用于很少改变的游戏内容。例如,当玩家进入游戏关卡时,仅编写一次的纹理可能需要加载多次。这些资产通常在打包分发时被压缩,在游戏进行时按需解压缩。将压缩应用于游戏资产以减少可下载内容的大小(及其安装占用空间)已成为标准做法。
然而,大多数数据压缩方案是为 CPU 设计的,并假定串行执行语义。事实上,数据压缩过程通常用基本上串行的术语来描述:在寻找冗余或重复模式的同时,对数据流进行串行扫描。它用对这些模式先前出现的引用来替换这些模式的多次出现。因此,此类算法无法轻松扩展到数据并行架构,也无法满足现代游戏内容所要求的更快解压缩速率的需求。
同时, I / O 技术的最新进展极大地提高了终端用户系统上的可用 I / O 带宽。消费者系统通常配备 PCIe Gen3 或 Gen4 NVMe 设备,能够提供高达 7 GB / s 的数据带宽。
从这个角度来看,按照这个速度,高端 NVIDIA GeForce RTX 4090 GPU 上的 24 GB 帧缓冲存储器可以在 3 秒钟内填满!
为了跟上这些系统级 I / O 速度的提高,我们需要在数据压缩技术方面取得巨大进步。在这些速率下,在最终用户的系统上使用 CPU 进行数据解压缩不再可行。这需要在这项辅助任务上花费大量宝贵的 CPU 周期。它还可能降低整个系统的速度。
CPU 不应该成为阻碍 I / O 子系统的瓶颈。
数据并行解压缩和 GDeflate 架构
随着摩尔定律的终结,我们再也不能指望从串行处理器中获得“免费”的性能改进。
高性能系统长期以来一直采用大规模数据并行,以继续扩展许多应用程序的性能。另一方面,传统数据压缩算法的并行化一直是一个挑战,因为基本的串行假设“烘焙”到了它们的设计中。
我们需要的是一种 GPU 友好的数据压缩方法,它可以随着 GPU 变得更宽和更并行而扩展性能。
这就是我们开始用 GDeflate 解决的问题,这是一种针对高通量 GPU 解压缩优化的新型数据并行压缩方案。我们设计 GDeflate 的目标如下:
- 高性能 GPU 优化解压缩以支持最快的 NVMe 设备
- 卸载 CPU 以避免其成为 I / O 操作期间的瓶颈
- 可移植到各种数据并行架构,包括 CPU 和 GPU
- 可以使用现有 IP 在固定功能硬件中廉价实现
- 建立数据并行数据压缩标准
正如您可以从名称中猜到的那样, GDeflate 建立在公认的 RFC 1951 DEFLATE 算法的基础上,对其进行扩展和调整,以适应数据并行处理。尽管存在更复杂的压缩方案,但原始 DEFLATE 数据编码的简单性和健壮性使其成为高度优化的基于 GPU 的实现的一个吸引人的选择。
DEFLATE 的现有固定函数实现也可以很容易地进行调整,以支持 GDeflate ,从而提高兼容性和性能。
两级并行
多核 SIMD 机器在设计上消耗 GDeflate 比特流,显式地暴露两个级别的并行性。
首先,原始数据流被分割成 64KB 的块,这些块被独立处理。这种粗粒度分解提供了线程级并行性,使多个瓦片能够在目标处理器的多个内核上并发处理。这也使得能够以瓦片粒度随机访问压缩数据。例如,流引擎可以请求根据给定帧的所需工作集来解压缩稀疏瓦片集。
此外, 64 KB 恰好是图形 API ( DirectX 和 Vulkan )中平铺或稀疏资源的标准平铺大小,这使得 GDeflate 与利用这些 API 功能的未来点播流架构兼容。
其次,瓦片内的比特流被专门格式化,以暴露更细粒度的 SIMD 级并行性。我们预计,一组协作线程将处理单个瓦片,因为该组可以使用硬件加速数据并行操作直接解析 GDeflate 比特流,这在大多数 SIMD 架构上都是可用的。
SIMD 组中的所有线程共享解压缩状态。比特流的格式被精心构造以实现对压缩数据的高度优化的协作处理。
这种两级并行化策略使 GDeflate 实现能够在广泛的数据并行架构中轻松扩展,同时为支持未来甚至更广泛的数据平行机提供了必要的空间,而不会影响解压缩性能。
NVIDIA RTX IO 支持 DirectStorage 1.1
NVIDIA RTX IO 现在包含在当前的 Game Ready 驱动程序(版本 526.47 )中,它提供了加速的解压缩吞吐量。
DirectStorage 和 RTX IO 都利用了 GDeflate 压缩标准。
“微软很高兴与 NVIDIA 合作,为 Windows 游戏玩家带来下一代 I / O 的好处。 DirectStorage for Windows 将使游戏能够利用 NVIDIA 的尖端 RTX IO ,并为游戏开发者提供一种高效、标准的方法,以从 GPU 中获得最佳性能和 I / O 系统。使用 DirectStorage ,游戏大小最小化,加载时间缩短,虚拟世界可以自由地变得更广阔和更详细,流媒体流畅无缝。”
Bryan Langley , Windows 图形和游戏组项目经理
RTX IO 驱动程序中的 DirectStorage 入门
我们还有一些建议可以帮助确保在 NVIDIA GPU 上使用 DirectStorage 和 GPU 解压缩的最佳体验。
为 DirectStorage 准备应用程序
使用具有 GPU 解压缩的 DirectStorage 实现最大端到端吞吐量需要将足够数量的读取请求排队,以保持管道完全饱和。
在准备 DirectStorage 集成时,应用程序应及时将资源 I / O 和创建请求分组在一起。理想情况下,资源 I / O 和创建操作发生在自己的 CPU 线程中,与执行其他加载屏幕活动(如着色器创建)的线程分开。
磁盘上的资产也应该打包成足够大的块,以便将 DirectStorage API 调用频率保持在最低水平,并将 CPU 成本降至最低。这确保可以向 DirectStorage 提交足够的工作,以保持管道完全饱和。
有关一般最佳实践的更多信息,请参见 Using DirectStorage 和 DirectStorage 1.1 Now Available Microsoft 帖子。
决定暂存缓冲区大小
- 确保在使用 GPU 解压缩时更改默认的暂存缓冲区大小。当前的 32 MB 默认值不足以使现代 GPU 功能饱和。
- 在决定暂存缓冲区大小时,请确保对具有不同 NVMe 、 PCIe 和 GPU 功能的不同平台进行基准测试。我们发现 128-MB 的暂存缓冲区大小是合理的默认值。较小的 GPU 可能需要更少,较大的 GPU 则可能需要更多。
压缩比注意事项
- 确保测量不同资源类型对压缩节省和 GPU 解压缩性能的影响。
- 通常,各种数据类型(如纹理和几何体)以不同的比率压缩。这可能导致 GPU 解压缩执行性能的一些变化。
- 这不会对端到端吞吐量产生重大影响。然而,当将资源内容传递到其最终位置时,这可能导致延迟的变化。
Windows 文件系统
- 尝试将 DirectStorage 访问的磁盘文件与其他 I / O API 访问的文件分开。跨不同 I / O API 的共享文件使用可能会导致旁路 I / O 改进的丢失。
后台流时的命令队列调度
- 在 Windows 10 中,命令队列调度争用可能发生在 DirectStorage 复制和计算命令队列以及应用程序管理的复制和计算指令队列之间。
- NVIDIA Nsight Systems 、 PIX 和 GPUView 工具可以帮助确定 DirectStorage 的后台流是否与重要的应用程序管理的命令队列发生冲突。
- 在 Windows 11 中, DirectStorage 和应用程序命令队列之间的重叠执行是完全预期的。
- 如果重叠执行导致应用程序工作负载的性能不理想,我们建议限制 DirectStorage 读取。这有助于在后台流传输时保持关键的应用程序性能。
总结
下一代游戏引擎需要大量的数据流,旨在创建越来越真实、详细的游戏世界。鉴于此,有必要重新思考游戏引擎的资源流架构,并充分利用 I / O 技术的改进。
使用 GPU 作为计算密集型加速器,数据解压缩对于最大化系统性能和减少加载时间至关重要。
GDeflate 的 NVIDIA RTX IO 实现是一种可扩展的 GPU 优化压缩技术,使应用程序能够从 GPU 的 I / O 加速计算能力中获益。它可以作为带宽放大器,实现当今和未来系统的高性能 I / O 功能。




