这是 解释 Magnum IO 系列的第三篇文章,目的是描述现代数据中心的 IO 子系统 Magnum IO 的体系结构、组件和优点。
本系列中的 第一个岗位 介绍了 Magnum IO 体系结构;将其定位在更广泛的 CUDA 、 CUDA -X 和垂直应用程序域中;并列出了体系结构的四个主要组件。 第二岗位 深入研究了 Magnum IO 的网络 IO 组件。第三篇文章涵盖了两个较短的领域:网络适配器或交换机中的计算和 IO 管理。无论您是对 InfiniBand 还是以太网感兴趣, NVIDIA Mellanox 解决方案都涵盖了您。
HDR 200G InfiniBand 和 NDR 400G ,下一代网络
InfiniBand 是 AI 超级计算的理想互连选择。根据 2020 年 11 月的 500 强超级计算机排行榜,全球前 10 强超级计算机中有 8 台正在使用它,前 100 强中有 60 台正在使用它。 InfiniBand 还加速了绿色 500 强超级计算机的速度。作为一种基于标准的互连, InfiniBand 享受着不断开发的新功能,以实现更高的应用程序性能和可扩展性。
InfiniBand 技术基于四个主要基础:
- 一种端点,可以在网络级别执行和管理所有网络功能,从而增加 CPU 或 GPU 时间,专门用于实际应用程序。 由于端点位于 CPU / GPU 内存附近,因此它还可以有效地管理内存操作,例如使用 RDMA 、 GPUDirect RDMA 和 GPUDirect 存储。
- 一种基于纯软件定义网络( SDN )的、按规模设计的交换网络。 例如, InfiniBand 交换机不需要每个交换机设备中都有嵌入式服务器来管理交换机和运行其操作系统。这使得 InfiniBand 成为与其他网络相比性价比领先的网络结构。简单的交换机架构为其他技术创新留下了空间,例如在网络计算中,在数据通过网络传输时对其进行操作。一个重要的例子是可伸缩的层次聚合和归约协议( SHARP )技术,它已经证明了科学和深度学习应用框架的巨大性能改进。
- 从一个地方集中管理整个 InfiniBand 网络。 您可以使用通用的 IB 交换机构建块设计和构建任何类型的网络拓扑,并为其目标应用程序定制和优化数据中心网络。不需要为网络的不同部分创建不同的交换机配置,也不需要处理多种复杂的网络算法。 InfiniBand 的创建是为了提高性能和减少运营成本。
- 前后兼容。 InfiniBand 是带有开放 API 的开源软件。
在 SuperComputing 20 上, NVIDIA 宣布了第七代 NVIDIA Mellanox InfiniBand 架构,其特点是 NDR 400Gb / s (每车道 100 Gb / s ) InfiniBand 。这使人工智能开发人员和科研人员能够以最快的网络性能应对世界上最具挑战性的问题。图 1 显示 InfiniBand 继续使用 NDR InfiniBand 设置性能记录:
- 每端口带宽为 400Gb / s ,数据传输速率提高 2 倍。
- 4 倍的消息传递接口( MPI )性能,适用于所有对所有操作,新的网络计算加速引擎适用于所有对所有操作。
- 更高的交换机基数,支持 64 个 400Gb / s 端口或 128 个 200Gb / s 端口。更高的基数可以在三跳 Dragonfly +网络拓扑中构建连接超过一百万个节点的低延迟网络拓扑。
- 最大的高性能交换机系统,基于无阻塞、两层胖树拓扑设计,提供 2048 个 400Gb / s 端口或 4096 个 200Gb / s 端口,共 1 . 6petabit 的双向数据吞吐量。
- 通过夏普技术提高了人工智能网络加速,使网络中的大型消息缩减操作的容量提高了 32 倍。

高速以太网: 200G 和 400G 以太网
以太网和 InfiniBand 各有其独特的优势。 NVIDIA Mellanox 用这对溶液覆盖碱基。有几种情况下,客户首选基于以太网的解决方案。有些存储系统只能使用以太网。人们对安全性越来越感兴趣,现有的协议是 IPSec ,这在 InfiniBand 上是不可用的。精确时间协议( PTP )用于以亚微秒的粒度在整个网络中同步时钟,例如用于高频交易。在许多情况下,基于以太网的编排和资源调配工具、监控安全性、性能调优、法规遵从性或技术支持的分析工具方面的长期专业知识是推动客户选择的原因,而不是其他成本或性能问题。
以太网和 InfiniBand 解决方案都与广泛关注的最佳实践工具(如 sFlow 和 NetFlow 网络监控和分析解决方案)以及自动化工具(如 Ansible 、 Puppet 和 SaltStack )进行互操作。
以太网已经变得无处不在,部分原因是它被认为易于配置和管理。但是, GPUDirect RDMA 和 GPUDirect Storage over Ethernet 要求将网络结构配置为支持 RDMA over Converged Ethernet ( RoCE )。在大多数网络供应商的设备上, RoCE 的配置和管理非常复杂。 NVIDIA Mellanox 以太网交换机通过使用单个命令启用 RoCE 以及提供 RoCE 特定的可见性和故障排除功能,消除了这种复杂性。
NVIDIA Mellanox 以太网交换机现在的运行速度高达 400 Gb / s ,提供了最高级别的性能,因为它们提供了市场上所有以太网交换机中最低的延迟数据包转发。 NVIDIA Mellanox 以太网交换机还提供独特的拥塞避免创新,为基于 RoCE 的工作负载提供应用程序级性能优势:

以太网交换机已被证明具有可扩展性,世界上所有最大的数据中心都使用简单且易于理解的叶和脊拓扑结构运行纯以太网结构。来自 NVIDIA 的以太网结构易于自动化, NVIDIA 提供的交钥匙 产品就绪自动化工具 免费提供并发布在 GitHub 上。
NVIDIA 的高速以太网交换机目前提供 100GbE 、 200GbE 甚至 400GbE 的速度,以实现基于以太网的存储和 GPU 连接的最高性能。
网络计算中的 InfiniBand
在网络计算引擎中,指位于网络适配器或交换机的数据路径上的预先配置的计算引擎。这些引擎可以在网络内传输数据时处理数据或对数据执行预定义的算法任务。这类引擎的两个例子是硬件 MPI 标记匹配和 InfiniBand SHARP 。
硬件标签匹配引擎
MPI 标准允许基于嵌入在消息中的标记来接收匹配的消息。处理每条消息以评估其标记是否符合感兴趣的条件既耗时又浪费时间。
MPI 发送/接收操作需要匹配的源和目标消息参数才能将数据传递到正确的目标。匹配的顺序必须遵循发送和接收的发布顺序。提供高效标记匹配支持的关键挑战包括:
- 管理标记匹配所需的元数据。
- 制作数据的临时副本以最小化标记匹配和数据传递之间的延迟。
- 跟踪未匹配的已过帐接收。
- 处理意外消息到达。
- 重叠标签匹配和相关的数据传递与正在进行的计算。
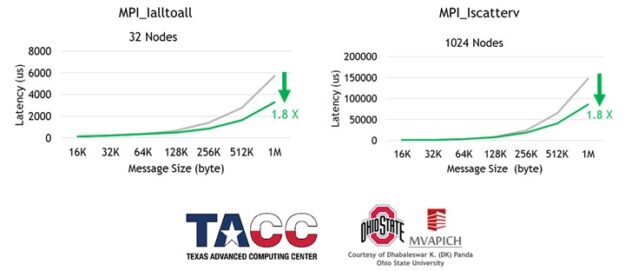
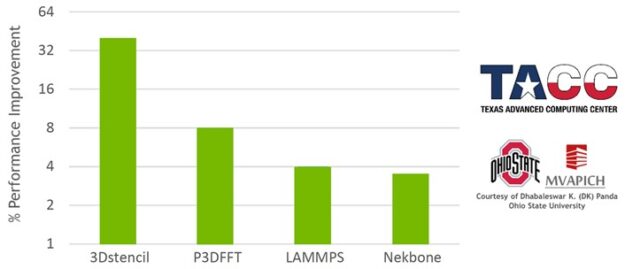
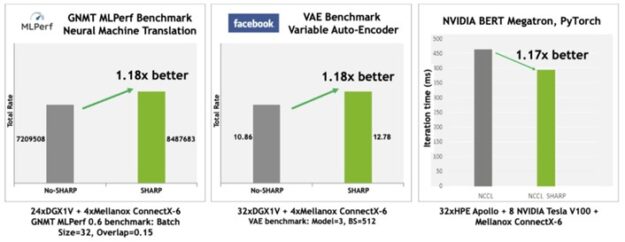
支持异步、基于硬件的标记匹配和数据传递是 ConnectX-6 (或更高版本)网络适配器的一部分。基于网络硬件的标记匹配减少了多个 MPI 操作的延迟,同时也增加了 MPI 计算和通信之间的重叠(图 3 和图 4 )。
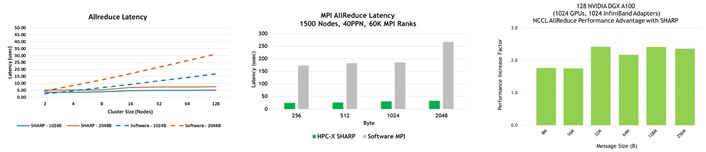
SHARP :可扩展的分层聚合和归约协议
NVIDIA Mellanox InfiniBand SHARP 通过在穿越网络时处理数据聚合和还原操作,提高了集合操作的性能,消除了在端点之间多次发送数据的需要。这种创新的方法不仅减少了通过网络的数据量,而且提供了额外的好处,包括释放宝贵的 CPU 资源用于计算,而不是用它们来处理通信开销。它还以异步方式进行此类通信,与主机处理状态无关。
如果没有 SHARP ,数据必须从每个端点发送到交换机,返回到计算集合的端点,返回到交换机,然后返回到端点。这是四个遍历步骤。使用 SHARP 时,集合操作发生在交换机中,因此遍历步骤的数量减少了一半:从端点到交换机,再返回。这使得这种集体操作的带宽提高了 2 倍, MPI allreduce 延迟降低了 7 倍(图 5 )。当然,吞吐量需求开销也会从 CPU 或 GPU 中除去,否则这些开销将用于计算。
- 支持的操作:
- 浮点数据: barrier 、 reduce 、 allreduce 、 broadcast 、 gather 和 allgather
- 有符号和无符号整数数据:大小为 64 、 32 和 16 位的操作数
- 支持的缩减操作: sum 、 min 、 max 、 minloc 、 maxloc 和按位 and 、 OR 和 XOR 。
SHARP 技术集成在大多数开源和商业 MPI 软件包以及 OpenSHMEM 、 NCCL 和其他 IO 框架中。
InfiniBand 和以太网 IO 管理
虽然提高性能是最终用户的兴趣所在,而清晰的体系结构有助于开发人员,但 IO 管理对于您作为管理员和所服务的最终用户来说至关重要。 NVIDIA Mellanox NetQ 和 UFM 管理平台使 IT 经理能够轻松配置、管理和优化其以太网连接数据中心( NetQ )或 InfiniBand 连接数据中心( UFM )操作。
以太网 NetQ
NVIDIA Mellanox 网络电话 是一个高度可扩展的现代网络操作工具集,可实时提供开放以太网的可见性、故障排除和生命周期管理。 NetQ 提供了关于数据中心和校园以太网健康状况的可操作的见解和操作智能,从容器或主机一直到交换机和端口,支持 NetDevOps 方法。 NetQ 是领先的以太网网络操作工具,它使用遥测技术从单个 GUI 界面进行深层次的故障排除、可见性和自动化工作流,减少维护和网络停机时间。
NetQ 还可以作为一种安全的云服务提供,这使得安装、部署和扩展网络更加容易。基于云的 NetQ 部署提供了即时升级、零维护和最小化设备管理工作。
通过添加完整的生命周期管理功能, NetQ 将轻松升级、配置和部署网络元素的能力与一整套操作功能结合起来,如可见性、故障排除、验证、跟踪和比较回溯功能。
NetQ 包括 Mellanox What Just ochapped ( WJH )先进的流式遥测技术,它通过提供异常网络行为的可操作细节,超越了传统的遥测解决方案。传统的解决方案试图通过分析网络计数器和统计数据包采样来推断网络问题的根本原因。 WJH 消除了网络故障排除中的猜测。
WJH 解决方案利用 NVIDIA Mellanox Spe CTR um 系列以太网交换机 ASIC 内置的独特硬件功能,以比基于软件或固件的解决方案更快的多 TB 速度检查数据包。 WJH 可以帮助诊断和修复数据中心网络,包括软件问题。 WJH 以线速率检查所有端口上的数据包,其速度超过了传统的深度数据包检查( DPI )解决方案。 WJH 为您节省了数小时的计算机软件故障排除、维护和维修现场技术支持服务。
InfiniBand 统一结构管理器

NVIDIA Mellanox InfiniBand Unified Fabric Manager UFM 平台彻底改变了数据中心网络管理。通过将增强的实时网络遥测与 AI 支持的网络智能和分析相结合, UFM 平台使 IT 经理能够发现运行异常并预测网络故障,以进行预防性维护。
UFM 平台包括多个级别的解决方案和功能,以满足数据中心的需求和要求。在基础层面, UFM 遥测平台提供网络验证工具,并监控网络性能和状况。例如,它捕获丰富的实时网络遥测信息、工作负载使用数据和系统配置,然后将其流式传输到已定义的内部部署或基于云的数据库以供进一步分析。
中端 UFM 企业平台增加了增强的网络监视、管理、工作负载优化和定期配置检查。除了包括所有 UFM 遥测服务外,它还提供网络设置、连接验证和安全电缆管理功能、自动网络发现和网络供应、流量监控和拥塞发现。 UFM Enterprise 还支持作业调度器配置和与 Slurm 或 Platform LSF 的集成,以及与 OpenStack 、 Azure 云和 VMware 的网络配置和集成。
增强型 UFM 网络人工智能平台包括所有 UFM 遥测和 UFM 企业服务。网络人工智能平台的独特优势在于,随着时间的推移,它能够捕获丰富的遥测信息,并使用深度学习算法。平台学习数据中心的“心跳”、操作模式、条件、使用情况和工作负载网络特征。它建立了一个增强的遥测信息数据库,并发现事件之间的相关性。它检测性能下降、使用情况和配置文件随时间的变化,并提供异常系统和应用程序行为以及潜在系统故障的警报。它还可以执行纠正措施。
网络人工智能平台可以转换和关联数据中心心跳的变化,以指示未来性能下降或数据中心计算资源的异常使用。这种变化和相关性触发预测分析,并启动警报,指示异常的系统和应用程序行为,以及潜在的系统故障。系统管理员可以快速检测和响应此类潜在的安全威胁,并以有效的方式解决即将发生的故障,从而节省运营成本并维护最终用户 SLA 。随着时间的推移,通过收集额外的系统数据,可预测性得到了优化。
概括
新一代的网络硬件和软件正在到来。它带来了更高的数据速率、更大的交换机系统容量,以及在单个交换机中实现 32 个独立操作的急剧分层缩减功能。尝试一些新技术:
- 下载 NVIDIA HPC-X MPI 系列 并试用适用于您的应用程序的硬件标记匹配和夏普。
- 请联系 NVIDIA 直接为您的应用程序使用 网络计算引擎中的 InfiniBand 。
- 使用 云中积云 在虚拟“实际操作”环境中尝试 NVIDIA 以太网交换。
- 体验更轻松的网络管理带来的好处,并探索如何使用 NetQ 和 WJH 用于以太网, UFM 用于 InfiniBand 优化网络操作。
- 了解有关新 Mellanox NDR InfiniBand technologies 公司 的更多信息。
- 了解有关今天发货的 Mellanox 200 和 400 千兆以太网交换机 的更多信息。
NVIDIA 致力于解决端到端的问题,从而获得突破性的解决方案。我们在将 CUDA 开发人员与应用程序开发人员联系起来方面有着良好的记录,应用程序开发人员为解决具有挑战性的问题提出了需求,并提供了高质量的复制品,我们还开发了新技术和修订的路线图,以进一步合作。我们邀请你们更深入地参与我们的工作,在新的科学领域做我们一生的工作!