
加速 GPU 应用程序的主要方法有三种:编译器指令、编程语言和预编程库。编译器指令,例如 OpenACC a 允许您顺利地将代码移植到 GPU 以使用基于指令的编程模型进行加速。虽然它易于使用,但在某些情况下可能无法提供最佳性能。
编程语言,例如 CUDA C 和 C ++ 在加速应用程序时为您提供更大的灵活性,但用户也有责任编写代码,利用新的硬件功能在最新的硬件上实现最佳性能。这就是预编程库填补空白的地方。
除了增强代码的可重用性外,还可以使用 NVIDIA 数学库 优化以充分利用 GPU 硬件,获得最大的性能增益。如果您正在寻找一种简单的方法来加速应用程序,请继续阅读,了解如何使用库来提高应用程序的性能。
NVIDIA 数学库,作为 CUDA 工具包 和 高性能计算( HPC )软件开发工具包( SDK ) ,提供各种计算密集型应用程序中遇到的函数的高质量实现。这些应用包括机器学习、深度学习、分子动力学、计算流体动力学( CFD )、计算化学、医学成像和地震勘探等领域。
这些库旨在取代常见的 CPU 库,如 OpenBLAS 、 LAPACK 和 Intel MKL ,并加速上的应用程序 NVIDIA GPU 代码更改最少。为了展示这个过程,我们创建了一个双精度通用矩阵乘法( DGEMM )功能的示例,以比较 cuBLAS 与 OpenBLAS 的性能。
下面的代码示例演示了 OpenBLAS DGEMM 调用的使用。
// Init Data
…
// Execute GEMM
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, m, n, k, alpha, A.data(), lda, B.data(), ldb, beta, C.data(), ldc);
下面的代码示例 2 显示了 cuBLAS dgemm 调用。
// Init Data
…
// Data movement to GPU
…
// Execute GEMM
cublasDgemm(cublasH, CUBLAS_OP_N, CUBLAS_OP_T, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc));
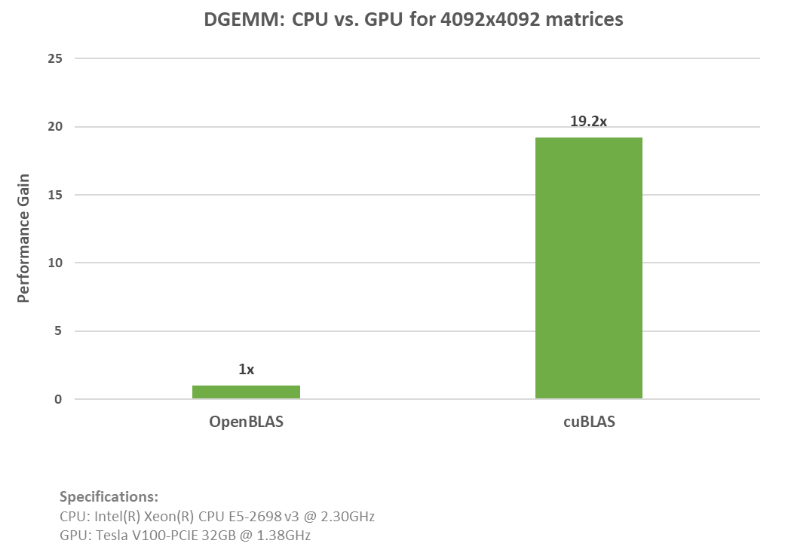
如上面的示例所示,您可以简单地添加 OpenBLAS CPU 代码并用 cuBLAS API 函数替换。 请参阅 cuBLAS 和 OpenBLAS 示例的完整代码 该 cuBLAS 示例在 NVIDIA ( R ) V100 张量核 GPU 上运行,速度提高了近 20 倍。下图显示了运行这些示例时的加速比和规格。
有趣的事实:这些库在更高级别的 Python API 中调用,例如 cuPy , cuDNN 和 RAPIDS ,因此,如果您有这些方面的经验,那么您已经在使用这些 NVIDIA 数学库。
这篇文章的其余部分涵盖了所有可用的数学库。有关最新更新和信息,请观看 NVIDIA 数学库的最新发展 .
与纯 CPU 替代方案相比,提供了更好的性能
有许多 NVIDIA 数学库可以利用,从 GPU 加速的 BLAS 实现到随机数生成。请看下面的 NVIDIA 数学库概述,了解如何开始轻松提高应用程序的性能。
用 cuBLAS 加速基本线性代数子程序
广义矩阵乘法是人工智能和科学计算中最常用的基本线性代数子程序之一。 GEMM 还构成了深度学习框架的基础模块。要了解有关在深度学习框架中使用 GEMM 的更多信息,请参阅 为什么 GEMM 是深度学习的核心 .
这个 cuBLAS 是 BLAS 的一种实现,它利用 GPU 功能实现了极大的速度提升。它包括用于执行向量和矩阵运算的例程,例如点积(级别 1 )、向量加法(级别 2 )和矩阵乘法(级别 3 )。
此外,如果您想并行化矩阵乘法, cuBLAS 支持多功能批量 GEMM ,可用于张量计算、机器学习和 LAPACK 。有关提高机器学习和张量收缩效率的更多详细信息,请参阅 CPU 和 GPU 上具有扩展 BLAS 核的张量收缩 .
古巴文字
如果问题太大,无法安装在 GPU 上,或者您的应用程序需要单节点、多 GPU 支持, 古巴文字 是一个很好的选择。 cuBLASXt 允许混合 CPU- GPU 计算,并支持执行矩阵到矩阵操作的 BLAS 级别 3 操作,例如执行厄米秩更新的herk。
cuBLASLt
cuBLASLt 是一个覆盖 GEMM 的轻量级库。 cuBLASLt 使用融合内核来加速应用程序,将两个或多个内核“组合”为单个内核,从而允许重用数据并减少数据移动。 cuBLASLt 还允许用户设置尾声的后处理选项(应用偏置,然后重新鲁变换或对输入矩阵应用偏置梯度)。
Cubrasmg : CUDA 数学库早期访问程序
对于大规模问题,请查看 Cubrasmg 以获得最先进的多 GPU 、多节点矩阵乘法支持。它目前是 CUDA 数学库早期访问程序的一部分。 申请访问权限。
用 cuSPARSE 处理稀疏矩阵
稀疏矩阵、密集矩阵乘法( SpMM )是机器学习、深度学习、 CFD 和地震勘探以及经济、图形和数据分析中许多复杂算法的基础。有效处理稀疏矩阵对于许多科学模拟至关重要。
神经网络规模的不断扩大以及由此产生的成本和资源的增加导致了稀疏化的需要。稀疏性在深度学习训练和推理中都得到了普及,以优化资源的使用。有关这一思想流派的更多信息以及对库(如 cuSPARSE )的需求,请参阅 深度神经网络稀疏性的未来 .
cuSPARSE 提供一组用于处理稀疏矩阵的基本线性代数子程序,这些子程序可用于构建 GPU 加速求解器。库例程有四类:
- 级别 1 在稀疏向量和密集向量之间运行,例如两个向量之间的点积。
- 级别 2 在稀疏矩阵和密集向量(例如矩阵向量积)之间运行。
- 第 3 级在稀疏矩阵和一组密集向量(例如矩阵乘积)之间运行。
- 级别 4 允许不同矩阵格式之间的转换和压缩稀疏行( CSR )矩阵的压缩。
cusPARSELt 公司
对于具有计算能力的 cuSPARSE 库的轻量级版本,可以执行稀疏矩阵密集矩阵乘法以及用于修剪和压缩矩阵的辅助函数,请尝试 cusPARSELt 。要更好地了解 CUSPASSELT 库,请参阅 使用 CUSPASSELT 利用 NVIDIA 安培结构稀疏性。
使用割传感器加速张量应用
这个 cuTENSOR 库 是一个张量线性代数库实现。张量是机器学习应用的核心,是推导应用问题控制方程的重要数学工具。 cuTENSOR 提供了直接张量收缩、张量约化和元素级张量运算的例程。 cuTENSOR 用于提高深度学习训练和推理、计算机视觉、量子化学和计算物理应用中的性能。
切割传感器
如果您仍然想要 cuTENSOR 功能,但支持可以在单个节点中跨多 GPU 分布的大张量,例如 DGX A100 , 切割传感器 是图书馆的首选。它提供了广泛的混合精度支持,其主要计算例程包括直接张量收缩、张量约化和元素级张量运算。
使用 cuSOLVER 的 GPU 加速 LAPACK 功能
这个 库索尔弗库 是一个用于基于 cuBLAS 和 cuSPARSE 库的线性代数函数的高级软件包。 cuSOLVER 提供了类似 LAPACK 的功能,例如矩阵分解、密集矩阵的三角形求解例程、稀疏最小二乘解算器和特征值解算器。
cuSOLVER 有三个独立的组件:
- cuSolverDN 用于密集矩阵分解。
- cuSolverSP 提供了一组基于稀疏 QR 分解的稀疏例程。
- cuSolverRF 是一个稀疏重分解包,用于求解具有共享稀疏模式的矩阵序列。
cusOLVERMg 公司
对于 GPU 加速的 ScaLAPACK 特性,考虑对称特征求解器、 1-D 列块循环布局支持以及对 cuSOLVER 特性的单节点多 GPU 支持 cusOLVERMg .
库索尔文普
求解大型线性方程组需要多节点、多 GPU 支持。以其上下分解和 Cholesky 分解特性而闻名, 库索尔文普 是一个很好的解决方案。
用 cuRAND 大规模生成随机数
这个 cuRAND 库 重点介绍通过主机( CPU ) API 或设备( GPU ) API 上的伪随机或准随机数生成器生成随机数。主机 API 可以纯粹在主机上生成随机数并将其存储在主机内存中,也可以在主机上调用库的设备上生成随机数,但随机数生成发生在设备上并存储在全局内存中。
设备 API 定义了用于设置随机数生成器状态和生成随机数序列的函数,用户内核可以立即使用这些函数,而无需对全局内存进行读写。一些基于物理的问题表明需要大规模随机数生成。
蒙特卡洛模拟是 GPU 上随机数生成器的一种用例。 在 CUDA Fortran 中开发基于 GPU 的蒙特卡洛并行伪随机神经网络 重点介绍了 cuRAND 在大规模生成随机数中的应用。
使用 cuFFT 计算快速傅立叶变换
cuFFT CUDA 快速傅立叶变换( FFT )库为在 NVIDIA GPU 上计算 FFT 提供了一个简单的接口。 FFT 是一种分治算法,用于有效计算复数或实值数据集的离散傅立叶变换。它是计算物理和一般信号处理中应用最广泛的数值算法之一。
cuFFT 可用于广泛的应用,包括医学成像和流体动力学。 光声显微镜定量血流成像的并行计算 说明了 cuFFT 在基于物理的应用程序中的使用。具有现有 FFTW 应用程序的用户应该使用 cuFFTW 轻松地将代码移植到 NVIDIA GPU 上,只需很少的努力。 cuFFTW 库提供了 FFTW3 API ,以便于移植现有的 FFTW 应用程序。
cuFFTXt
要在单个节点中跨 GPU 分布 FFT 计算,请检查 cuFFTXt .该库包括帮助用户在多个 GPU 上操作数据和跟踪数据顺序的功能,从而可以以最有效的方式处理数据。
cuFFTMp
不仅在单个系统中有多 GPU 支持, cuFFTMp 提供跨多个节点的多 GPU 支持。该库可用于任何 MPI 应用程序,因为它独立于 MPI 实现的质量。它使用 NVSHMEM 这是一个基于 OpenSHMEM 标准的通信库,专为 NVIDIA GPU 设计。
cuFFTDx
要通过避免不必要的全局内存访问并允许 FFT 内核与其他操作融合来提高性能,请查看 cuFFT 设备扩展( cuFFTDx ) 作为数学库设备扩展的一部分,它允许应用程序在用户内核内计算 FFT 。
使用 CUDA 数学 API 优化标准数学函数
CUDA 数学 API 是为每种 NVIDIA GPU 架构优化的标准数学函数的集合。所有 CUDA 库都依赖于 CUDA 数学库。 CUDA 数学 API 支持所有 C99 标准浮点和双精度数学函数、浮点、双精度和全舍入模式,以及不同的函数,如三角函数和指数函数(cospi、sincos)和其他逆误差函数(erfinv、erfcinv)。
使用带弯刀的 C ++模板自定义代码
矩阵乘法是许多科学计算的基础。这些乘法在深度学习算法的有效实现中尤为重要。与库布拉斯类似, CUDA Templates for Linear Algebra Subroutines (CUTLASS) 包含一组线性代数例程,用于执行有效的计算和缩放。
它结合了分层分解和数据移动的策略,类似于用于实现 cuBLAS 和 cuDNN 的策略。然而,与 cuBLAS 不同的是,弯刀越来越模块化和可重新配置。它将 GEMM 的运动部分分解为基本组件或块,作为 C ++模板类可用,从而为您定制算法提供了灵活性。
该软件是流水线的,以隐藏延迟并最大限度地提高数据重用。无冲突地访问共享内存,以最大限度地提高数据吞吐量,消除内存占用,并完全按照您想要的方式设计应用程序。要了解有关使用 Cutslass 提高应用程序性能的更多信息,请参阅 CUDA C 中的快速线性代数++ .
使用 AmgX 计算微分方程
AmgX 提供 GPU 加速的 AMG (代数多重网格)库,在分布式节点上的单个 GPU 或多 GPU 上受支持。它允许用户创建复杂的嵌套解算器、平滑器和预条件器。该库使用不同的平滑器(如块 Jacobi 、 Gauss-Seidel 和稠密 LU )实现了经典和基于聚合的代数多重网格方法。
该库还包含预条件 Krylov 子空间迭代方法,如 PCG 和 BICGStab 。 AmgX 为模拟的计算密集型线性求解器部分提供高达 10 倍的加速度,非常适合隐式非结构方法。
AmgX 是专门为 CFD 应用开发的,可用于能源、物理和核安全等领域。 AmgX 库的一个实际示例是求解小规模到大规模计算问题的泊松方程。
这个 飞蛇模拟示例 显示了在 GPU 上使用 AmgX 包装器加速 CFD 代码时所花费的时间和成本的减少。与一个 12 核 CPU 节点相比,一个 K20 GPU 节点上有 300 万个网格点,速度提高了 21 倍。
开始使用 NVIDIA 数学库
- cuBLAS 、 cuRAND 、 cuFFT 、 cuSPARSE 、 cuSOLVER 和 CUDA 数学库都包含在 HPC SDK NVIDIA 和 CUDA 工具包
- 数学库设备扩展( cuFFTDx )在 MathDx 20.22
- cuTENSOR , cusPARSELt 和 MathDx 可以在上找到 开发区
- AmgX 和 CUTLASS 在 GitHub 上可用
- Cubrasmg 目前是 CUDA 数学库早期访问程序
我们继续努力改进 NVIDIA 数学库。如果您有任何问题或新功能请求,请联系产品经理 马修很好 .
致谢
我们非常感谢 Matthew 的指导和积极反馈。特别感谢安妮塔·维梅斯的所有反馈和她在整个过程中的持续支持。




