对语音识别技术感兴趣?注册我们的 语音 AI 新闻稿 .
语音人工智能是一种能够使用语音与计算机系统进行通信的技术。指挥车内助手或操作智能家居设备?支持人工智能的语音界面可以帮助您与设备交互,而无需在屏幕上键入或点击。
人工智能的语音领域相对较新。但随着语音交互的成熟并扩展到新的设备和平台,开发人员必须跟上不断发展的术语。
在本文中,我介绍了语音人工智能领域的关键概念,描述了它在更大的人工智能领域中的位置,并讨论了它与其他科学技术领域的关系。
基本概念
您可能听说过,甚至熟悉这些技术,但为了完整起见,以下是一些基本知识:
- 人工智能 ( AI )是指创造与人类认知能力相匹配或超过人类认知能力的智能机器的广泛学科。
- 机器学习 ( ML )是人工智能的一个子领域,涉及创建方法和系统,学习如何使用过去的数据执行特定任务。
- 深度学习 ( DL )是一系列 ML 方法,基于 人工神经网络 具有多个层次,通常使用大量数据进行训练。
语音人工智能系统如何与人工智能、 ML 和 DL 相关?
语音人工智能是将人工智能用于基于语音的技术。语音人工智能系统的核心组件包括:
- 一自动语音识别(语音识别) 该系统也称为语音到文本、语音识别或语音识别。这将语音信号转换为文本。
- A.文本到语音( TTS )该系统也称为语音合成。这将文本转换为语音形式。
语音人工智能是 对话人工智能 ,主要从 DL 和 ML 领域绘制其技术。 AI 、 ML 、 DL 和语音 AI 之间的关系可以用图 1 中的维恩图表示。
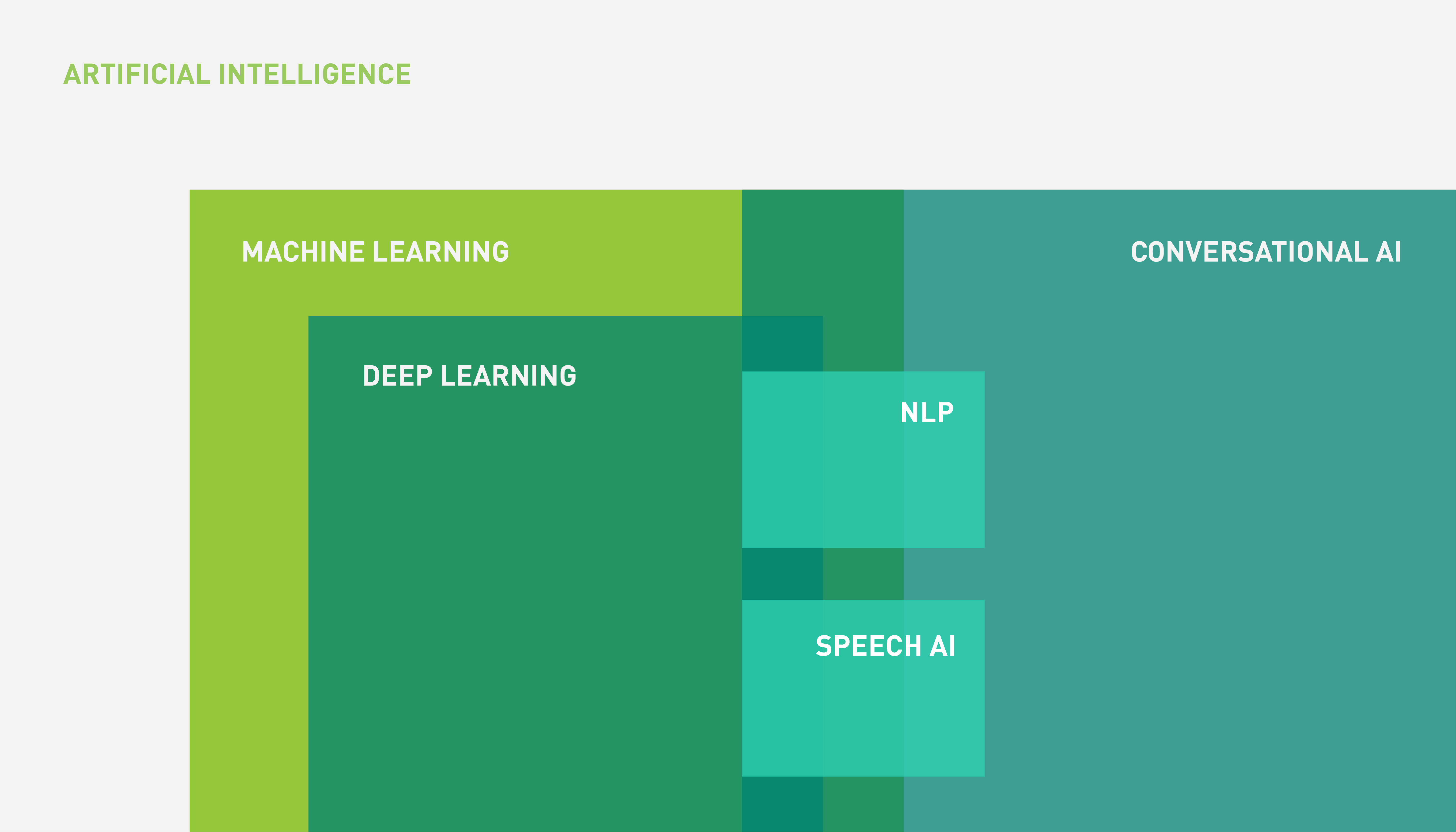
图 1 显示,会话人工智能是基于语言的应用程序的更大范围,其中并非所有应用程序都包括语音组件(语音)。
以下是语音人工智能技术如何与其他工具和技术并肩工作,形成一个完整的对话人工智能系统。
对话人工智能
对话人工智能是一门涉及设计智能系统的学科,该系统能够通过自然语言以对话的方式与人类用户进行交互。商业示例包括家庭助理和聊天机器人(例如,保险索赔聊天机器人或旅行社聊天机器人)。
对话可以有多种模式,包括音频、文本和手语,但当输入和输出是口语自然语言时,就有了一个基于语音的对话人工智能系统(图 2 )。
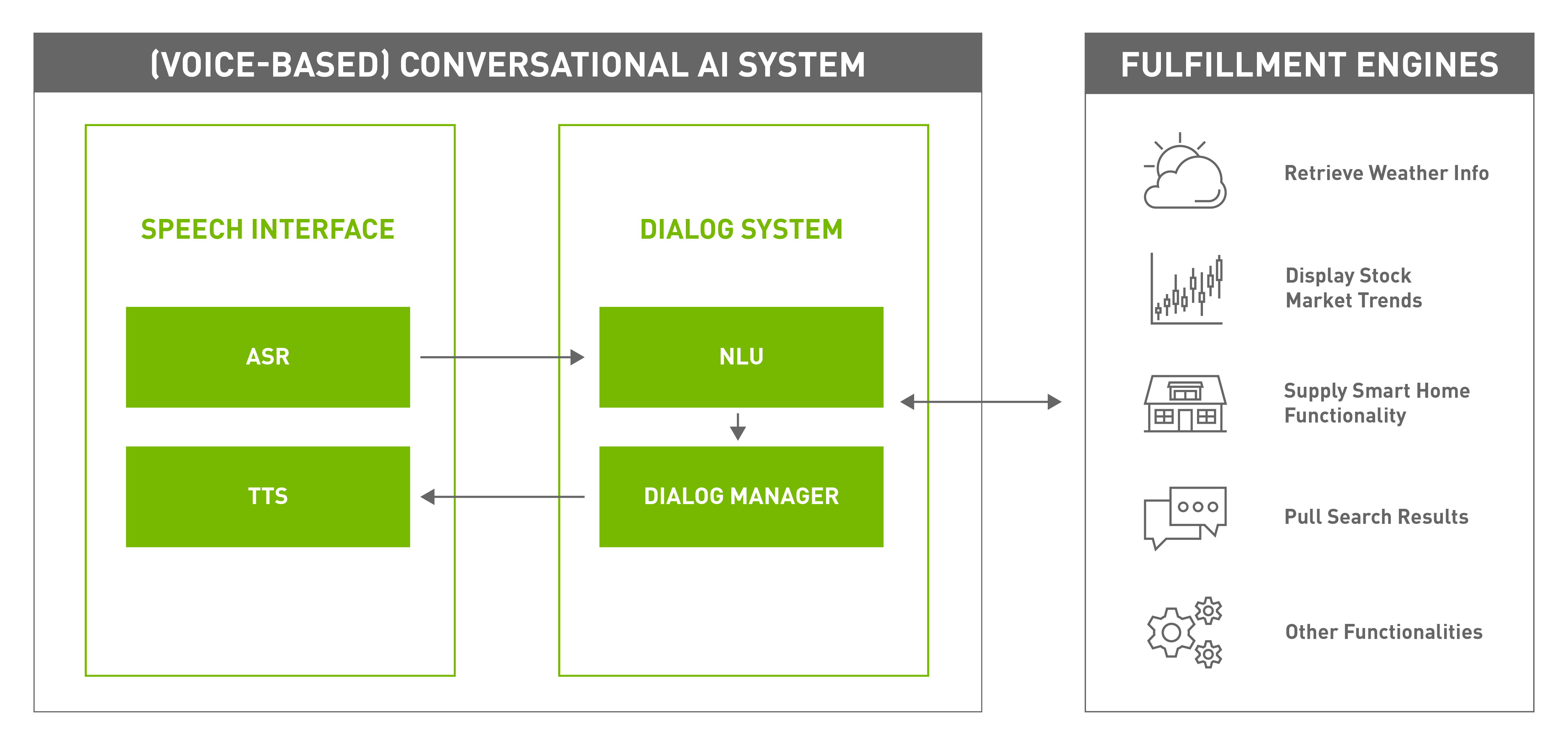
典型的基于语音的对话人工智能系统的组件包括:
- A.语音接口通过语音人工智能技术,使系统能够通过自然语言口语格式与用户交互。
- A.对话系统管理与用户的对话,同时与外部履行系统交互,以满足用户的需求。它由两部分组成:
- 这个履行引擎执行对话人工智能系统的功能性任务,例如:检索天气信息、阅读新闻、订票、提供股市信息、回答琐事问答等等。一般来说,它们不被视为对话人工智能系统的一部分,而是紧密合作以满足用户的需求。
语音人工智能概念
在本节中,我们将深入探讨语音人工智能的特定概念:自动语音识别和文本到语音。
自动语音识别
典型的基于深度学习的 ASR 管道包括五个主要组件(图 3 )。
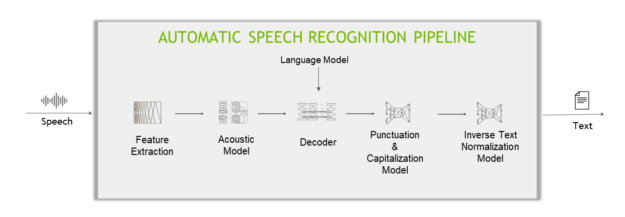
特征提取程序
特征提取器将音频信号分割为固定长度的块(也称为时间步长),然后将这些块从时域转换为频域。
声学模型
这种机器学习模型(通常是多层深度神经网络)预测音频数据每个时间步的字符概率。
译码器和语言模型
译码器将声学模型给出的概率矩阵转换为字符序列,字符序列依次生成单词和句子。
语言模型( LM )可以给出一个分数,表示句子出现在其训练语料库中的可能性。例如,在英语语料库上训练的 LM 会判断“识别语音”比“毁掉一个漂亮的桃子”更可能,同时也会判断“ Je suis un é tudiant ”不太可能(因为这是一个法语句子)。
当与 LM 结合时,解码器将能够将其“听到的”(“我午餐吃玫瑰牛肉”)更正为更符合常识的内容(“我午餐吃烤牛肉”),因为 LM 对后一句话的评分高于前者。
标点和大写模式
标点和大写模型添加标点并大写解码器生成的文本。
反向文本规范化模型
最后,应用反向文本规范化( ITN )规则将文字格式转换为所需的书面格式,例如,“十点”到“ 10 : 00 ”,或“十美元”到“ 10 美元”。
其他 ASR 概念
文字错误率 ( WER )和字符错误率( CER )是 ASR 系统的典型性能指标。
WER 是错误数除以口语单词总数。例如,如果在总共 50 个口语单词中有 5 个错误, WER 将为 25% 。
除字符而非文字外, CER 的操作方式类似。日语和普通话等语言没有用特定标记或定界符分隔的“单词”(如英语的空格)。
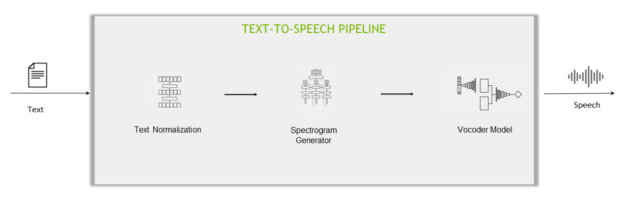
文本到语音( TTS )
文本到语音步骤通常使用两种不同的方法实现:
- A.两级管道:分别训练两个独立的网络以将语音转换为文本:频谱图生成器网络和声码器网络。
- 一端到端管道:使用一个模型直接从文本生成音频。
两态管道的组成部分包括:
- 文本规范化模型:将书面格式的文本转换为口头格式,例如,“ 10 : 00 ”到“ 10 点”,“ 10 美元”到“ 10 美元”。这是 ITN 的相反过程。
- 频谱图发生器网络:TTS 管道的第一阶段使用神经网络从文本生成频谱图。
- 声码器网络:TTS 管道的第二阶段将来自频谱图生成器网络的频谱图作为输入,并生成自然发音语音。
语音合成标记语言
其他 TTS 概念包括语音合成标记语言( SSML ),它是一种基于 XML 的标记语言,允许您指定如何将输入文本转换为合成语音。您的配置可以使用音高、发音、语速和音量等参数使生成的合成语音更具表现力。
常见的 SSML 标记包括以下内容:
- 韵律学用于自定义生成语音的基音、语速和音量。
- 音素用于手动覆盖生成的合成语音中单词的发音。
平均意见分数
为了评估 TTS 引擎的质量, 平均意见分数 ( MOS )经常使用。 MOS 源于电信领域,定义为人类评估人员在主观质量评估测试中对提供的刺激给出的算术平均值。
例如,一个常见的 TTS 评估设置是一群人听生成的样本,并给每个样本一个从 0 到 5 的分数。然后将 MOS 计算为总体评估者和测试样本的平均分数。
如何开始使用语音人工智能
语音人工智能如今已成为主流,成为消费者日常生活中不可或缺的一部分。企业正在发现通过整合语音人工智能功能为其产品带来附加值的新方法。
获得语音人工智能专业知识的最好方法是体验它。有关如何为对话人工智能应用程序构建和部署实时语音人工智能管道的更多信息,请参阅免费的 构建语音人工智能应用程序 电子书.