作为一名数据科学家,评估机器学习模型性能是您工作的一个关键方面。为了有效地做到这一点,您可以使用各种统计指标,每种指标都有自己独特的优势和劣势。通过对这些指标的深入理解,您不仅可以更好地选择最佳指标来优化模型,还可以向业务利益相关者解释您的选择及其影响。
在这篇文章中,我重点讨论了用于评估回归问题的指标,这些回归问题涉及到预测一个数值,无论是房价还是下个月公司销售额的预测。由于回归分析可以被认为是数据科学的基础,因此理解其中的细微差别至关重要
残留物快速入门
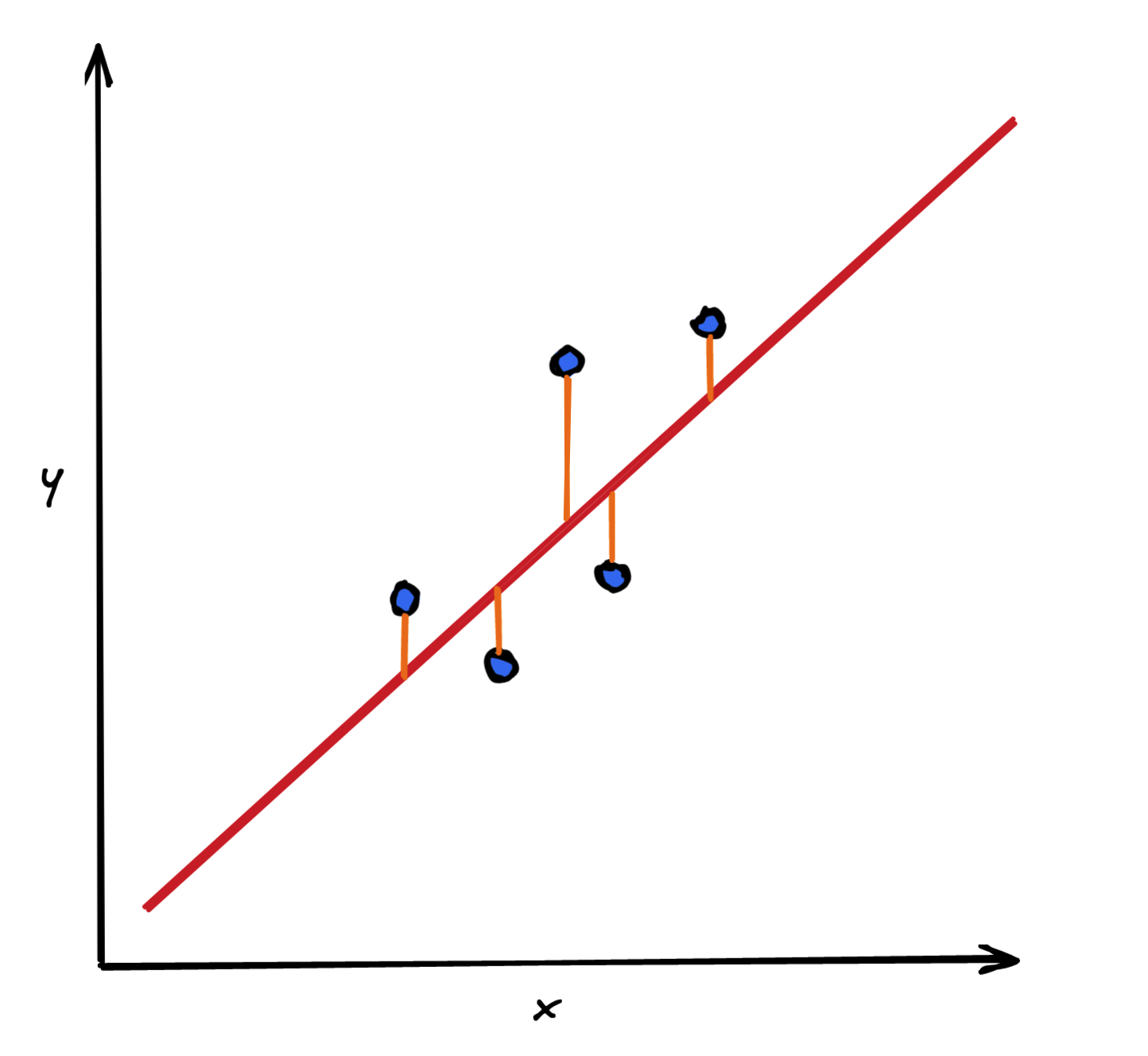
残差是大多数度量的构建块。简单地说,残差是实际值和预测值之间的差值
residual = actual - prediction图 1 显示了目标变量之间的关系 (y) 和一个功能 (x) . 蓝点代表观察结果。红线是机器学习模型的拟合,在这种情况下线性回归橙色线表示观测值与该观测的预测值之间的差异。正如您所看到的,残差是为样本中的每个观测值计算的,无论是训练集还是测试集。
回归评估指标
本节讨论了一些最流行的回归评估指标,这些指标可以帮助您评估模型的有效性。
偏见
最简单的误差度量是残差之和,有时被称为偏差。由于残差既可以是正的(预测值小于实际值)也可以是负的(预测大于实际值),所以偏差通常会告诉你的预测值是高于还是低于实际值
然而,由于相反符号的残差相互抵消,您可以获得一个生成偏差非常低的预测的模型,而该模型根本不准确。
或者,您可以计算平均残差,或者平均偏误( MBE )。
R 平方
下一个指标可能是你在学习回归模型时遇到的第一个指标,尤其是在统计学或计量经济学课程中。R 平方 ( R ²),也称为决定系数,表示由模型解释的方差比例。更准确地说, R ²对应于因变量(目标)的方差可以由自变量(特征)解释的程度
以下公式用于计算 R ²:
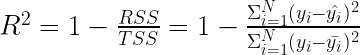
- RSS 是残差平方和,即残差平方和。此值捕获模型的预测误差。
- TSS 是平方的总和。为了计算这个值,假设一个简单的模型,其中每个观测的预测是所有观测到的实际值的平均值。 TSS 与因变量的方差成比例,如下所示
是的实际方差y哪里N是观测次数.把 TSS 想象成一个简单的均值模型无法解释的方差
实际上,您正在比较模型(由图 2 中的红线表示)与简单平均模型(由绿线表示)的拟合。
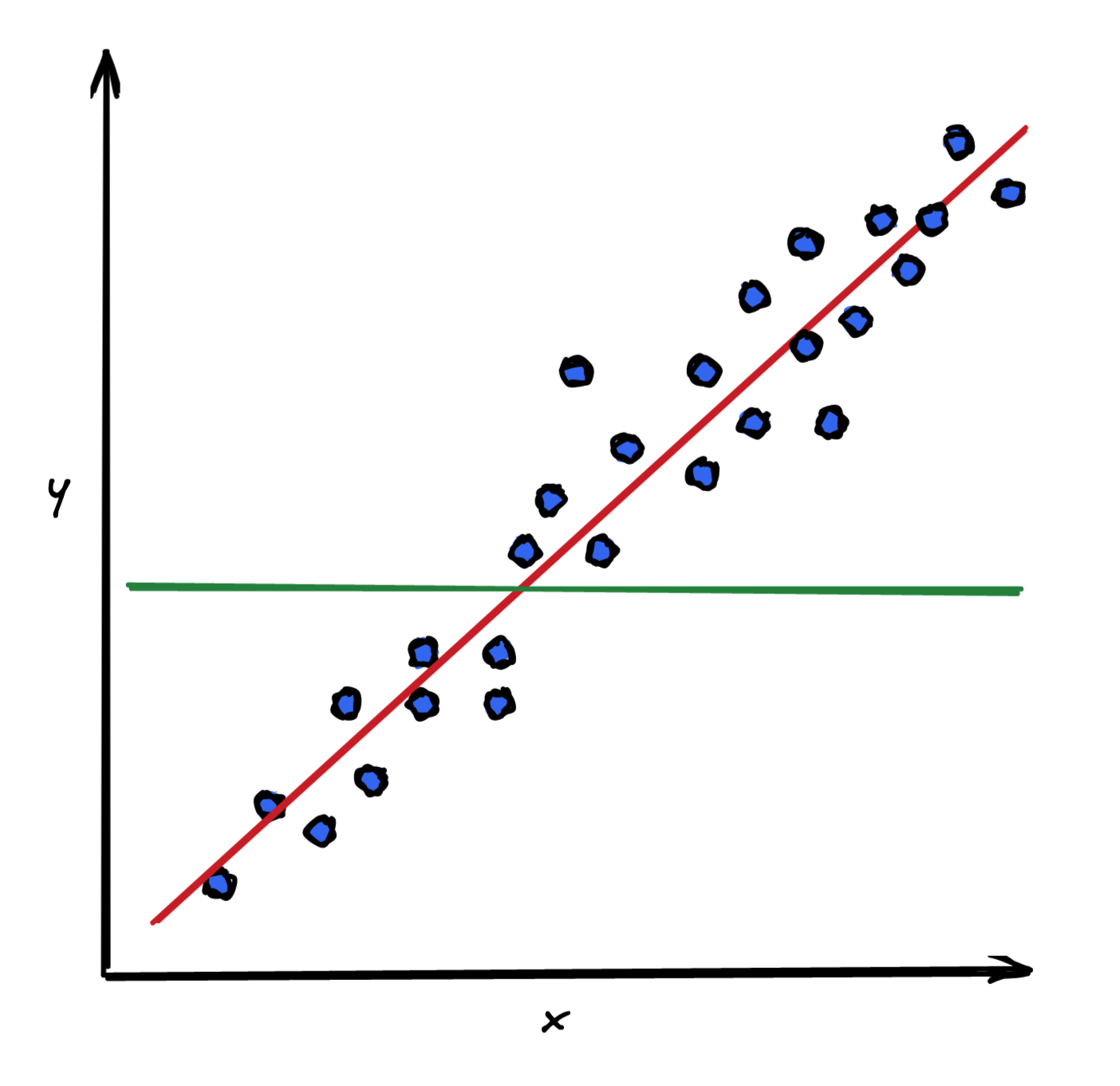
知道 R ²的组成部分代表什么,你可以看到
在使用 R ²时,需要记住以下几点。
R ²是一个相对度量;也就是说,它可以用来与在同一数据集上训练的其他模型进行比较。值越高表示拟合效果越好。
R ²也可以用来粗略估计模型的总体性能。然而,在使用 R ²进行此类评估时要小心:
- 首先,不同的领域(社会科学、生物学、金融等)认为 R ²的不同值是好是坏。
- 其次, R ²没有给出任何偏差的度量,所以你可以有一个 R ²值很高的过拟合(高偏差)模型。因此,您还应该查看其他指标,以更好地了解模型的性能。
R ²的一个潜在缺点是,它假设每个特征都有助于解释目标的变化,而事实并非总是如此。因此,如果继续将特征添加到使用普通最小二乘法( OLS )估计的线性模型中, R ²的值可能会增加或保持不变,但永远不会减少。
为什么?通过设计, OLS 估计使 RSS 最小化。假设一个具有附加特征的模型不能提高第一个模型的 R ²值。在这种情况下, OLS 估计技术将该特征的系数设置为零(或一些统计上不重要的值)。反过来,这会有效地将您带回初始模型。在最坏的情况下,你可以得到起点的分数。
上一点提到的问题的解决方案是调整后的 R²,它额外惩罚添加对预测目标无用的特征。如果由于添加新功能而导致的 R² 增加不够显着,则调整后的 R² 的值会降低。
如果使用 OLS 拟合线性模型,则 R ²的范围为 0 到 1 。这是因为当使用 OLS 估计(使 RSS 最小化)时,一般属性是RSS ≤ TSS 。在最坏的情况下, OLS 估计将导致获得平均模型。在这种情况下, RSS 将等于 TSS ,并导致 R ²的最小值为 0 。另一方面,最好的情况是 RSS = 0 和 R ²= 1 。
在非线性模型的情况下, R ²可能是负的。由于此类模型的模型拟合过程不是基于迭代最小化 RSS ,因此拟合模型的 RSS 可能大于 TSS 。换句话说,该模型的预测比简单均值模型更适合数据。有关更多信息,请参阅When is R squared negative?
额外的好处:使用 R ²,您可以评估与简单均值模型相比,您的模型更适合数据。从提高基线模型性能的角度来考虑一个正的 R ²值——类似于技能得分。例如, 40% 的 R ²表示您的模型与基线(即均值模型)相比,均方误差减少了 40% 。
均方误差
均方误差( MSE )是最流行的评估指标之一。如以下公式所示, MSE 与残差平方和密切相关。不同的是,您现在感兴趣的是平均误差,而不是总误差。

使用 MSE 时需要考虑以下几点:
- MSE 使用平均值(而不是总和)来保持度量与数据集大小无关。
- 随着残差的平方, MSE 对大误差的惩罚要大得多。其中一些可能是异常值,因此 MSE 对它们的存在并不稳健。
- 由于度量是用平方、和和常数来表示的 (
) ,它是可微的。这对优化算法很有用。
- 在对 MSE 进行优化(将其导数设置为 0 )时,该模型的目标是预测的总和等于实际的总和。也就是说,它导致了平均正确的预测。因此,他们是不偏不倚的。
- MSE 不是以原始单位测量的,这可能会使其更难解释
- MSE 是尺度相关度量的一个例子,也就是说,误差以基础数据的单位表示(即使它实际上需要一个平方根来以相同的尺度表示)。因此,此类度量不能用于比较不同数据集之间的性能。
均方根误差
均方根误差( RMSE )与 MSE 密切相关,因为它只是后者的平方根。取平方将度量带回目标变量的刻度,这样更容易解释和理解。然而,请注意:一个经常被忽视的事实是,尽管 RMSE 与目标的规模相同,但 RMSE 为 10 并不意味着你平均减少了 10 个单位。

除了规模之外, RMSE 具有与 MSE 相同的属性。事实上,在训练模型的同时对 RMSE 进行优化将产生与在对 MSE 进行优化时获得的模型相同的模型。
平均绝对误差
要计算的公式平均绝对误差( MAE )类似于 MSE 公式。将正方形替换为绝对值

MAE 的特点包括:
- 由于缺乏平方,度量以与目标变量相同的比例表示,因此更容易解释
- 所有误差都被同等对待,因此度量对异常值是鲁棒的。
- 绝对值忽略了误差的方向,因此欠填=过填。
- 与 MSE 和 RMSE 类似, MAE 也依赖于规模,因此无法在不同的数据集之间进行比较。
- 当您为 MAE 进行优化时,预测值必须比实际值高出许多倍,因为它应该更低。这意味着你正在有效地寻找中位数;也就是说,一个将数据集拆分为两个相等部分的值
- 由于公式包含绝对值,因此 MAE 不容易微分。
平均绝对百分比误差
平均绝对百分比误差( MAPE )是商业方面最受欢迎的指标之一。这是因为它是以百分比表示的,这使得它更容易理解和解释。
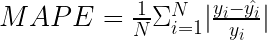
为了使度量更容易阅读,将其乘以 100% ,以百分比表示数字。
需要考虑的要点:
- MAPE 以百分比表示,这使它成为一个与尺度无关的度量。它可以用来比较不同尺度上的预测
- MAPE 可以超过 100% 。
- 当实际值为零时(除以零), MAPE 是未定义的。此外,当实际值非常接近零时,它可以取极值。
- MAPE 是不对称的,对负误差(当预测高于实际值时)的惩罚比对正误差的惩罚更重。这是因为对于过低的预测,百分比误差不能超过 100% 。同时,对于过高的预测没有上限。因此,对 MAPE 的优化将有利于预测不足而不是预测过度的模型。
- Hyndman ( 2021 )阐述了 MAPE 的常见假设;也就是说,变量的测量单位有一个有意义的零值。因此,预测需求和使用 MAPE 不会引发任何危险信号。然而,当预测以摄氏度表示的温度时,你会遇到这个问题(不仅仅是这个)。这是因为温度有一个任意的零点,在它们的上下文中谈论百分比是没有意义的。
- MAPE 不是处处可微的,这可能会导致在使用它作为优化准则时出现问题。
- 由于 MAPE 是一个相对度量,相同的误差可能会导致不同的损失,具体取决于实际值。例如,对于 60 的预测值和 100 的实际值, MAPE 将是 40% 。对于 60 的预测值和 20 的实际值,标称误差仍然是 40 ,但在相对尺度上,它是 300% 。
- 不幸的是, MAPE 并不能提供一种很好的方法来区分重要的和不相关的。假设你正在进行需求预测,在几个月的时间里,你会得到两种不同产品 10% 的 MAPE 。然后,事实证明,第一款产品平均每月销售 100 万台,而另一款只有 100 台。两者具有相同的 10%MAPE 。当对所有产品进行汇总时,这两种产品的贡献是相等的,这可能远远不够理想。在这种情况下,考虑加权 MAPE ( wMAPE )是有意义的。
对称平均绝对百分比误差
在讨论 MAPE 时,我提到它的一个潜在缺点是它的不对称性(不限制高于实际值的预测)。对称平均绝对百分比误差( sMAPE )是一个试图解决该问题的相关指标。

使用 sMAPE 时需要考虑的要点:
- 它表示为有界百分比,也就是说,它有下限( 0% )和上限( 200% )。
- 当真实值和预测值都非常接近零时,度量仍然不稳定。当它发生时,你将处理一个非常接近零的数字的除法。
- 0% 到 200% 的范围解释起来并不直观。分母中的除以二经常被省略。
- 每当实际值或预测值为 0 时, sMAPE 将自动达到上限值。
- sMAPE 包括与 MAPE 相同的关于有意义零值的假设。
- 在固定无边界的不对称性的同时, sMAPE 引入了另一种由公式的分母引起的微妙不对称性。想象两个案例。在第一个例子中, A = 100 , F = 120 。 sMAPE 为 18 . 2% 。现在,在类似的情况下,当 a = 100 和 F = 80 时, sMAPE 是 22 . 2% 。因此, sMAPE 倾向于比过度加注更严厉地惩罚加注不足。
- sMAPE 可能是最具争议的误差度量之一,尤其是在时间序列预测中。这是因为文献中至少有几个版本的这种度量,每个版本都有轻微的差异,影响其性质。最后,度量的名称表明不存在不对称性,但事实并非如此。
需要考虑的其他回归评估指标
我没有描述所有可能的回归评估指标,因为有几十个(如果不是几百个的话)。以下是评估模型时需要考虑的其他一些指标:
- 均方对数误差( MSLE )是 MSE 的表亲,不同之处在于,在计算平方误差之前,您需要对实际值和预测值进行对数。在减法中取两个元素的对数,结果是测量实际值和预测值之间的比率或相对差异,而忽略了数据的规模。这就是为什么 MSLE 减少了异常值对最终得分的影响。 MSLE 还加大了对欠充注的惩罚力度
- 均方根对数误差( RMSLE )是一个以 MSLE 的平方根为单位的度量。它具有与 MSLE 相同的属性
- Akaike 信息准则( AIC )和贝叶斯信息准则( BIC )是信息标准的例子。它们用于在良好的拟合和模型的复杂性之间找到平衡。如果你从一个简单的模型开始,添加一些参数,你的模型可能会更好地适应训练数据。然而,它的复杂性也会增加,并有过度拟合的风险。另一方面,如果从许多参数开始,并系统地删除其中一些参数,则模型会变得更简单。同时,您可以降低过拟合的风险,但可能会损失性能(拟合优度)。 AIC 和 BIC 之间的区别在于复杂性惩罚的权重。请记住,将不同数据集甚至同一数据集的子样本上的信息标准与不同数量的观测值进行比较是无效的。
何时使用每个评估指标
与大多数数据科学问题一样,没有单一的最佳指标来评估回归模型的性能。为用例选择的度量将取决于用于训练模型的数据、您试图帮助的商业案例等等。因此,您可能经常使用单个度量来训练模型(为其优化的度量),但在向利益相关者报告时,数据科学家通常会提供一系列度量。
在选择指标时,请考虑以下几个问题:
- 您预计数据集中会出现频繁的异常值吗?如果是这样的话,你想如何解释它们?
- 是否存在过度加注或加注不足的商业偏好?
- 您想要一个与规模相关的度量还是与规模无关的度量?
我认为探索一些玩具箱的指标以充分理解它们的细微差别是有用的。虽然大多数指标在metrics的模块scikit-learn对于这个特定的任务,好的旧电子表格可能是一个更合适的工具。
以下示例包含五个观察结果。表 1 显示了用于计算大多数考虑的度量的实际值、预测和一些度量。
| y | _帽子 | 残余物 | 平方误差 | abs 错误 | abs perc 错误 | sAPE |
| 100 | 120 | -20 | 400 | 20 | 20% | 18 . 18% |
| 100 | 80 | 20 | 400 | 20 | 20% | 22 . 22% |
| 80 | 100 | -20 | 400 | 20 | 25% | 22 . 22% |
| 200 | 240 | -40 | 1 , 600 | 40 | 20% | 18 . 18% |
| 40 | 5 | 35 | 1225 | 35 | 87 . 50% | 155 . 56% |
| 毫秒 | 805 |
| RMSE | 28 . 37 |
| 高级工程师 | 27 |
| 地图 | 34 . 50% |
| sMAPE | 47 . 27% |
前三行包含实际值和预测值之间的绝对差为 20 的场景。前两行显示了 20 的过量和不足,实际情况相同。第三行显示了 20 的超额预测,但实际值较小。在这些行中,很容易观察到 MAPE 和 sMAPE 的特殊性。
表 1 中的第五行包含比实际值小 8x 的预测。为了实验起见,将预测值替换为比实际值高 8 倍的预测值。表 3 包含修订后的意见。
| y | _帽子 | 残余物 | 平方误差 | abs 错误 | abs perc 错误 | sAPE |
| 100 | 120 | -20 | 400 | 20 | 20% | 18 . 18% |
| 100 | 80 | 20 | 400 | 20 | 20% | 22 . 22% |
| 80 | 100 | -20 | 400 | 20 | 25% | 22 . 22% |
| 200 | 240 | -40 | 1 , 600 | 40 | 20% | 18 . 18% |
| 40 | 320 | -280 | 78 , 400 | 280 | 700% | 155 . 56% |
| 毫秒 | 16240 |
| RMSE | 127 . 44 |
| 高级工程师 | 76 |
| 地图 | 157% |
| sMAPE | 47 . 27% |
基本上,所有指标的大小都呈爆炸式增长,这在直觉上是一致的。 sMAPE 的情况并非如此,在两种情况下都保持不变
我强烈鼓励您参考这些玩具示例,以便更充分地了解不同类型的场景如何影响评估指标。这个实验应该让你更容易决定优化哪个指标以及这种选择的后果。这些练习也可以帮助你向利益相关者解释你的选择。
总结
在这篇文章中,我介绍了一些最流行的回归评估指标。正如所解释的,每一个都有自己的优点和缺点。这取决于数据科学家来理解这些,并选择哪一个(或多个)适合特定的用例。所提到的度量也可以应用于纯回归任务,例如基于与经验相关的特征选择来预测工资,也可以应用到时间序列预测领域。
如果你想建立能够有效处理异常值的稳健线性回归模型,请参阅我之前的文章,Dealing with Outliers Using Three Robust Linear Regression Models.
工具书类
Jadon , A .、 Patil , A .和 Jadon , S .( 2022 )。用于时间序列预测的基于回归的损失函数的综合综述。arXiv 预印本 arXiv : 2211 . 02989.
Hyndman , R . J .( 2006 年)。另一个关注间歇性需求的预测准确性指标。远见:国际应用预测杂志,4(4) , 43-46 .
Hyndman , R . J .和 Koehler , A . B .( 2006 年)。再看一下预测准确性的衡量标准。国际预测杂志,22(4) , 679-688 .
Hyndman , R . J .和 Athanasopoulos , G .( 2021 )预测:原理与实践,第 3 版, OTexts :澳大利亚墨尔本。 OTexts . com / fp3 。