Apply for Early Access to NVIDIA NeMo Microservices
NVIDIA NeMo™ is an end-to-end platform for building and customizing enterprise-grade generative AI models that can be deployed anywhere, across cloud and data centers. NeMo microservices provide the easiest way to customize and evaluate generative AI models while supporting retrieval-augmented generation (RAG) in applications. Explore the microservices available in our early access program and apply below.
How to Apply
To request early access, follow these steps:
Register for an Account
Early access to NeMo microservices requires an NVIDIA Developer Program account, which also gives you access to exclusive learning resources to accelerate your generative AI development.
Apply for Early Access
Fill out one of the request forms below to apply to your desired early access program.
Await Email Confirmation
If your request is approved, you'll receive a welcome email. Please make sure nvidia.com domains are added to your safe list to avoid emails being flagged as spam.
Access the Member’s Page
A link will be included in your approval email. Follow this link to get to the members’ portal, resources, and NVIDIA NGC™, where you can access the microservices.

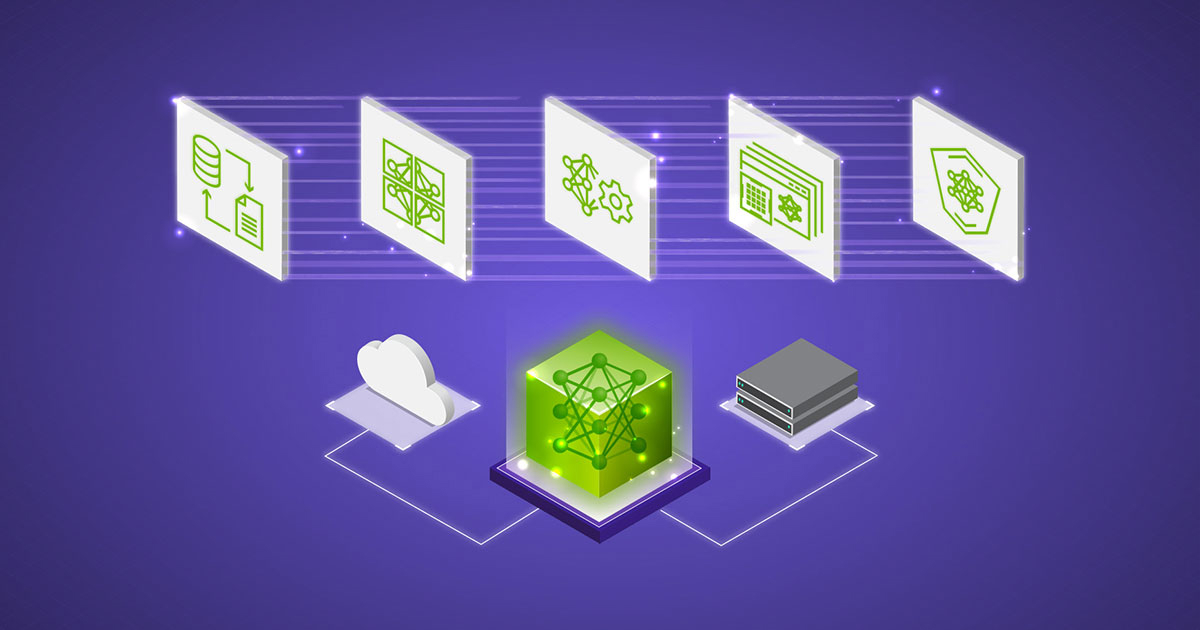
NVIDIA NeMo Microservices for Generative AI
NeMo provides microservices that simplify the generative AI development and deployment process at scale, allowing organizations to connect LLMs to their enterprise data sources:
NVIDIA NeMo Curator enables high-quality dataset generation for LLM training.
NVIDIA NeMo Customizer simplifies the fine-tuning and alignment of models while accelerating performance and scalability.
NVIDIA NeMo Evaluator provides automatic assessment across various academic and custom benchmarks, delivering fast, easy, and reliable evaluation of custom large language models (LLMs) and RAGs.
NVIDIA NeMo Retriever, a collection of generative AI microservices, enables organizations to seamlessly connect custom models to diverse business data and deliver highly accurate responses. NeMo Retriever includes world-class information retrieval with the lowest latency, highest throughput, and maximum data privacy, letting organizations make better use of their data and generate business insights in real-time.
Coming Soon - The NVIDIA RAG LLM Operator makes it easy to deploy your RAG application into production. The operator deploys RAG pipelines, developed using NVIDIA’s example workflows, into production without rewriting any code
To participate, please fill out the short application and provide details about your use case. You must be a member of the NVIDIA Developer Program and log in with your organization's email address. Applications from personal email accounts will be declined.
After approval, users will need to sign a non-disclosure agreement (NDA) to receive access.
NVIDIA NeMo Service
The NVIDIA NeMo service allows for easy customization and deployment of LLMs for enterprise use cases. NeMo is currently in private, early access. This early access program provides:
A playground to use and experiment with LLMs, including instruct-tuned models for different business needs
The ability to customize a pretrained LLM using p-tuning techniques for a domain-specific use case or task
The ability to deploy LLMs on premises or cloud, experiment via the playground, or use the service’s customization or inference APIs
To participate, please fill out the short application and provide details about your use case. You must be a member of the NVIDIA Developer Program and log in with your organization's email address. Applications from personal email accounts will be declined.
After approval, users will need to sign an NDA to receive access.