Explicit Multi-GPU with DirectX 12 – Control, Freedom, New Possibilities
This blog post is about explicit multi-GPU programming that became possible with the introduction of the DirectX 12 API. In previous versions of DirectX, the driver had to manage multiple SLI GPUs. Now, DirectX 12 gives that control to the application. There are two parts in this blog post. In this first part, I’ll explain how multiple GPUs are exposed in the DirectX API, giving some pointers to the API documentation. Please look for further details in the documentation itself. In the second part, I’ll describe a technique called frame pipelining - a new way for utilizing multiple GPUs that was not possible before DirectX 12.
Background
Since the launch of SLI, a long time ago, utilization of multiple GPUs was handled automatically by the display driver. The application always saw one graphics device object no matter how many physical GPUs were behind it. With DirectX 12, this is not the case anymore. But why start doing something manually that has been working automatically? Because, actually, for a good while before DirectX 12 arrived, the utilization of multiple GPUs has not been that automatic anymore.
As rendering engines have grown more sophisticated, the distribution of rendering workload automatically to multiple GPUs has become problematic. Namely, temporal techniques that create data dependencies between consecutive frames make it challenging to execute alternate frame rendering (AFR), which still is the method of choice for distribution of work to multiple GPUs. In practice, the display driver needs hints from the application to understand which resources it must copy from one GPU to another and which it should not. Data transfer bandwidth between GPUs is very limited and copying too much stuff can make the transfers the bottleneck in the rendering process. Giving hints to the driver can be implemented with NVAPI or by making additional Clear() or Discard() calls for selected resources.
Consequently, even when you didn’t have explicit control over multiple GPUs, you had to understand what happened implicitly and give the driver hints for doing it efficiently in order to get the desired performance out of multi-GPU setups. Now with DirectX 12, you can take full and explicit control of what is happening. And you are no longer limited to AFR. You are free to invent new ways of making use of multiple GPUs that better suit your application.
Adapters - Multiple or Linked Together
DirectX 12 exposes two alternate ways of controlling multiple physical GPUs. They can be controlled as multiple independent adapters where each adapter represents one physical GPU. Alternatively, they can be configured as one “linked node adapter” where each node represents one physical GPU. However, it’s important to note that application cannot control how it sees multiple GPUs. It cannot link or unlink adapters. The selection is done by end user through display driver settings.

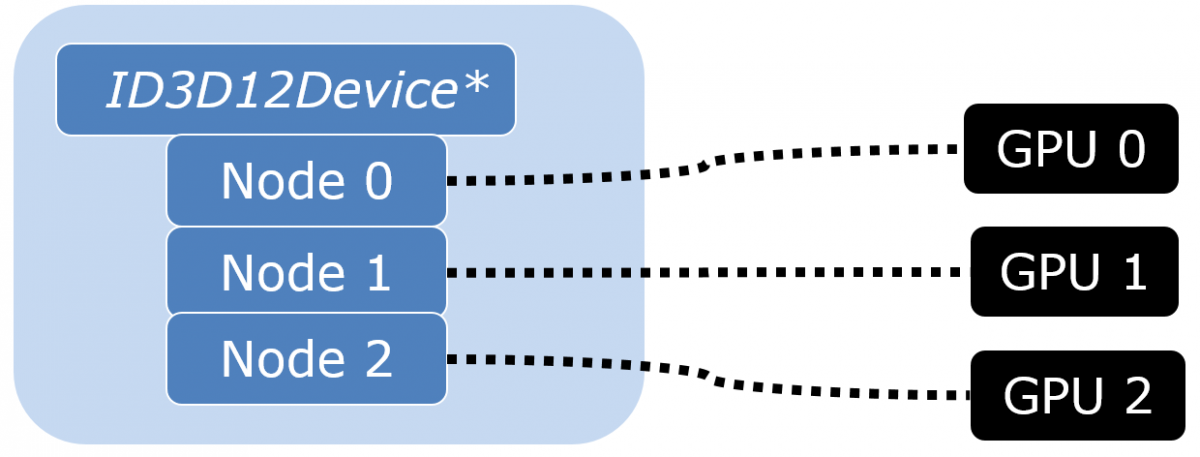
In practice, the linked node mode is meant for multiple equal, discrete GPUs, i.e. classic SLI setups. It offers a couple of important benefits. Within a linked node adapter, resources can be copied directly from memory of one discrete GPU to memory of another. The copy doesn’t have to pass through system memory. Additionally, when presenting frames from secondary GPUs in AFR, there’s a special API for supporting connections other than PCIe. (See IDXGISwapChain3::ResizeBuffers1() in DirectX documentation.)

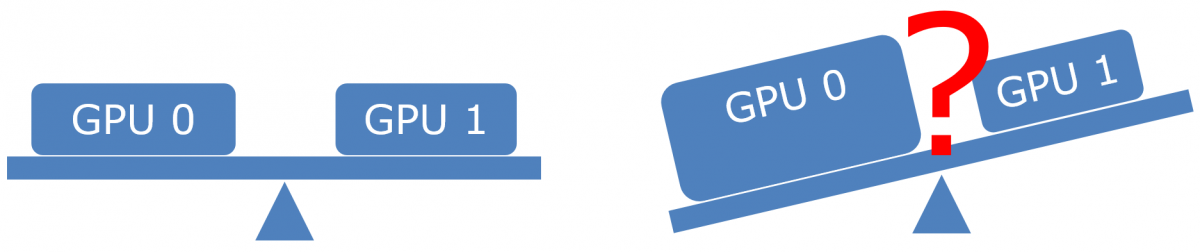
Today, all available linked node implementations link only equivalent GPUs. In practice, applications can build their load balancing between the nodes on this assumption. However, the linked node API doesn’t actually guarantee that nodes have equal performance. Someday, heterogeneous linked node adapters may be available making the load balancing less trivial.
In this blog post, I’ll focus on linked node adapter due to its suitability for classic multi GPU setups.
Engine requirements
To explicitly utilize multiple GPUs, the renderer needs to be aware of their existence. This requires some new code infrastructure. Building the infrastructure can actually be the task that requires most effort. Once the infrastructure exists, it’s easier to experiment with different ways of utilizing all the GPUs in the system.
When using a linked node adapter, you create one ID3D12Device as you would with a single physical GPU. But various objects that you create through the ID3D12Device use node affinity masks to identify the nodes with which the object is associated. The affinity mask is a bitmask where each bit represents one node (physical GPU). Some objects are exclusive to one physical GPU meaning that exactly one bit in the node mask must be set. Others can be associated with (or created on) arbitrary GPUs.
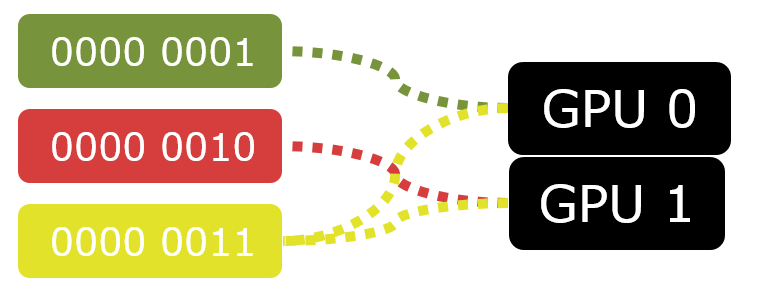
For example, when you create a ID3D12CommandQueue for submitting work to the GPU, you specify a node mask to identify the physical GPU to which the command queue feeds work. The ID3D12CommandQueue is one of the APIs that are exclusive to one node. Likewise, the ID3D12CommandList objects are exclusive to one node. As a result, you have to replicate your command list pooling system for each node. ID3D12PipelineState, on the other hand, is an example of an object that can be associated with arbitrary nodes. You don’t have to create separate object for each node. The same pipeline state object can be set to command lists associated with any node.
When sharing resources, the application is responsible for synchronizing the command queues to avoid access conflicts. Also, the application must ensure that the queues see resources in the same state, i.e. the resource barriers set by different command queues must match. ID3D12Fence is the synchronization tool that is used for these purposes.

DirectX 12 exposes “copy engines”, i.e. command queues that accept only command lists containing copy operations such as ID3D12GraphicsCommandList::CopyResource(). Copy engines are special hardware that can perform copy operations at the same time as graphics and compute engines are doing other work. They are additional parallel processing power available for copy operations. The number of copy engines available at hardware level varies on each GPU model, but a safe assumption is that there is at least one hardware copy engine available per each physical GPU. The copy engines are very useful in multi-GPU programming. Copying resources over PCIe bus is slow and the copy engines allow other processing on the GPU to go on while they are doing the slow copy operations. (However, copy engines are not good for copies within a physical GPU because they are not designed to operate faster than the PCIe bus allows. Graphics and compute engines are much faster for this purpose. Copy engines do have their place on single-GPU systems - for copying from system memory to video memory over the PCIe bus.)

In a linked node adapter, there is a tier system for cross node sharing functionality. Tier 1 supports only copy operations on resources residing on other nodes. Tier 2 supports using resources through SRVs, CBVs and UAVs in draw and dispatch calls. The tier 2 functionality may seem convenient, but the parallel copy engines cannot do draw or dispatch calls and slowing down the other engines with cross node resource access is usually not wise.
When creating resources, you specify two separate node affinity masks: CreationNodeMask and VisibleNodeMask. The CreationNodeMask determines the node where the resource physically resides. VisibleNodeMask determines the nodes on which the resource is mapped for access. In the CreationNodeMask, exactly one bit must be set but in the VisibleNodeMask, arbitrary bits can be set. When a resource is accessed from other than creation node, data is transferred between nodes. The transferred data may be cached to avoid retransfer when it’s accessed again but the application should not rely on this. There are no guarantees about the caching behavior. I.e. the application cannot ensure that a given resource stays in cache and it cannot see whether or not a given resource is still in cache. For achieving reliable performance, manually replicating art assets (vertex buffers, textures etc) for each node that uses them is recommended. I.e. don’t just create resources on one node and make them visible to others. Using them through SRVs from other nodes is possible, but there’s no guarantees about the performance.
ID3D12DescriptorHeap objects are exclusive to one node. This means that regardless of whether you replicate the resource objects for each node that uses them or not, the resource views must be replicated in any case. Though when cross node access happens with copy engine, resource views are not used. Copy engine access just needs properly set bits in VisibleNodeMask.
If you implement classic AFR, you should manually duplicate all your resources to all nodes. This includes art assets, render targets and constant buffers and other dynamic resources. On each frame, you use the resources that reside on the node doing the rendering for that frame. You upload dynamic data from CPU to resources on that node and render to target resources on that node using asset resources residing on that node. The transfer of the rendered frame to the primary node (the node to which the monitor is attached) for presentation on screen is best done using the special API provided for it. (See again IDXGISwapChain3::ResizeBuffers1()). Possible data dependencies between the frames should be handled with additional resource copy operations using the copy engine.
This concludes part 1. The second part of the blog post examines frame pipelining, one new alternative to classic AFR that’s now possible with the exposed functionality.
To read part 2, click here: Explicit Multi-GPU with DirectX 12 – Frame Pipelining, a New Alternative