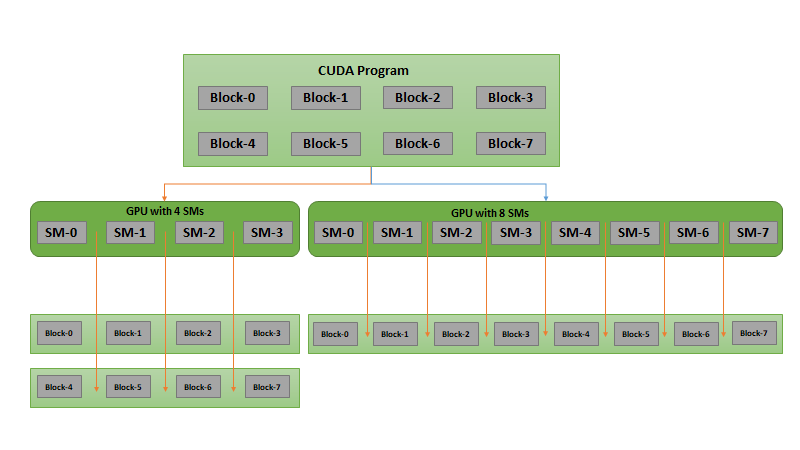
Well, that was embarrassing. Ever since NVIDIA Developer Zone was compromised by hackers in July, most of the DevZone content has been offline while NVIDIA’s crack team of web infrastructure and security engineers improve security. Unfortunately for me and you, dear reader, Parallel Forall was sidelined.
But we haven’t been resting on our laurels! On the contrary; we’ve toiled away for the great day when Parallel Forall comes back to life, planning and writing useful parallel programming content. Gregory Ruetsch and I have been busy writing two parallel (pun intended) series, “Programming CUDA with Fortran” (by Greg), and “Programming CUDA with C and C++” (by me). These series will start from the beginning to teach you how to program CUDA in your choice of Fortran or C/C++. We’ll cover the basics of writing and launching kernels, measuring performance, handling errors, efficiently transferring data, and much more.
Not all the content we have planned is for beginners, though. There will also be more advanced posts, including a post or two about efficiently building tree data structures in CUDA, by Tero Karras. We’re also planning to take deeper looks at some of the new features in CUDA 5, the CUDA Compiler SDK, and other interesting topics.
Even with a full pipeline, I’m always looking for great ideas for posts. So please use the contact form linked in the sidebar to tell us what you would like to hear about in the future. You can also contact me on twitter at @harrism.
Welcome back!