The NVIDIA Base Command Platform enables an intuitive, fully featured development experience for AI applications. It was built to serve the needs of the internal NVIDIA research and product development teams. Now, it has become an essential method for accessing on-demand compute resources to train neural network models and execute other accelerated computing experiments.
Base Command Platform simplifies AI experimentation workflows by providing a cohesive service that integrates users, jobs, and data. It provides easy access to a private registry to host custom containers as well as the breadth of software from the NGC Catalog. It offers all these features without sacrificing reliable NVIDIA performance, flexibility, and scalability. You can use Base Command Platform for experiments requiring a single GPU or a data center’s worth of them.
Base Command Platform interface and features
Base Command Platform supports a CLI, API, and web interface, all built into the NGC portal. The integrated web interface makes software discovery in the NGC Catalog and subsequent use in Base Command Platform smooth. You don’t have to transition between tools not designed to be used together.
In addition to providing access to the public NGC Catalog, you also gain access to a private registry dedicated to the Base Command Platform environment. The private registry is useful for keeping containers, models, and software private and secure, as dictated by developer requirements.
Base Command Platform provides a rich set of user management controls. When you are invited to use a Base Command Platform environment (called an organization), the administrator can restrict your ability to upload and interact with content on the platform through a set of role-based access controls. These controls can apply to the root organization and also to the concept of a team.
A team can differ minimally or significantly from the root organization, depending on how an admin configures that team. For example, a team may only be provided access to a subset of private registry containers or resources. When onboarded to a team, you could be disallowed from uploading your own containers to the private registry.
These capabilities can be mixed and matched to provide the right level of functionality for a given user or group by the org administrator. Administrators can also set hardware usage quotas in the organization for specific users, both GPU and storage capacity.
The Base Command Platform web interface places the key user interaction points front and (left of) center:
- Jobs: A list of containers running on NVIDIA Base Command Platform compute resources.
- Datasets: Read-only data inputs that can be mounted into jobs.
- Workspaces: Read/write persistent storage that can also be mounted into jobs.
Simple yet powerful hardware abstraction
In Base Command Platform, the managed hardware resources are presented to the user through two concepts: accelerated computing environments (ACEs) and instances within an ACE.
An ACE is a composition of a set of hardware resources: compute, network, and storage. An instance selects the CPU, RAM, and GPU resource quantities that a job requires from a system within an ACE.
ACEs can support a variety of instance types depending on their underlying hardware composition. Administrators can restrict the use of these resources through a quota for GPU hours, as well as completely restricting instance type availability for specific users in the org.
Base Command Platform resources are connected through industry-leading technology provided by the underlying infrastructure. NVIDIA NVLink, NVIDIA InfiniBand, and high-performance Ethernet connectivity are integrated as part of a Base Command Platform environment’s design to maximize the value of the managed hardware resources.
The scheduler in Base Command Platform is designed to take advantage of topology awareness to provide optimal resource use for jobs as they are submitted.
Datasets and workspaces
Data management is core to Base Command Platform’s capabilities. Datasets, models, and source code must be made available to compute resources during experimentation.
The dataset and workspace concepts are how Base Command Platform solves this problem. A dataset is a read-only storage construct after creation, with all the same sharing capabilities as private registry contents. They can be private to a specific user, shared with any number of teams in an org, or shared with the entire org.
Workspaces are more flexible. They are readable and writable but can be marked read-only when used in a job if desired. Workspace-sharing capabilities are identical to what datasets support.
Datasets are created through either the web interface or the CLI at upload or conversion time. We cover conversion when jobs are discussed later in this post. A workspace is created first, then populated with data as part of a job, or through direct upload (similar to datasets).
So, why would you use one over the other?
Datasets are a great fit for immutable data that must be widely shared as-is. Frequently, that is a dataset that no longer requires modification but could also include a license file or API key intended for shared use. They can be shared widely because there is no chance that they will be modified in place.
Workspaces are a great fit as a landing place for data that is a work-in-progress: datasets, source code maintained outside a container, or even a collection of models under development. Workspaces can be shared widely but given that they are writable by default, wide sharing may require additional coordination and awareness between users.
The aggregate dataset and workspace capacity available for a given user in Base Command Platform is controlled by the user’s storage quota, set by the org administrator. You can see your storage quota along with your current storage usage on the Base Command Platform dashboard.
There is an additional storage type, result, that factors into this capacity, which we discuss later in the context of jobs. When your quota is exceeded, you can request additional capacity if enabled by your environment administrator.
Bringing it all together in a job
Base Command Platform operationalizes data, compute resources, the NGC Catalog, and private registry contents with jobs.
Job creation starts with resource selection. You are presented with available ACEs for use by your org and team. You may have access to more than one ACE, but a job must execute within a single ACE.
After an ACE is selected, you can select from the available instance types in that ACE. For multi-node jobs, the only instances available are those that leverage the maximum CPU, RAM, and GPU resources available for a given system type within the selected ACE.
Choose an ACE, an instance type, and multi-node launch options, if necessary. Next, you can specify datasets and workspaces that are a part of the chosen ACE to be mounted into the target job, along with the desired mount point for each of them. Here, a workspace can be marked as read-only.
The job’s result storage path must be specified as well. A result is a job-specific read/write storage pool intended to hold artifacts that you’d like to preserve from the job upon completion, along with stderr and stdout. As we mentioned previously, the capacity consumed by results counts against your quota.
Then, you must select a Container object and a valid container Tag. You can choose containers from the NGC Catalog as well as the private registry containers that you have permission to access. If you select a multi-node job, only containers marked in the NGC Catalog or private registry as supporting multi-node functionality are presented as options.
You now specify one or more commands, or even a service (such as JupyterLab, Visual Studio Code Server, or NVIDIA Triton Inference Server) to run inside the selected container when the job is active. If an external port is needed to expose a web interface or some other endpoint, one or more ports must be added with the Add a Container Port option.
Now that the job is specified, there are several more options available to configure:
- Job priority level
- New job name
- How a job is capable of behaving if preempted
- Maximum runtime of the job
- Time slice interval for telemetry collection
- Custom labels
Interacting with running and finished jobs
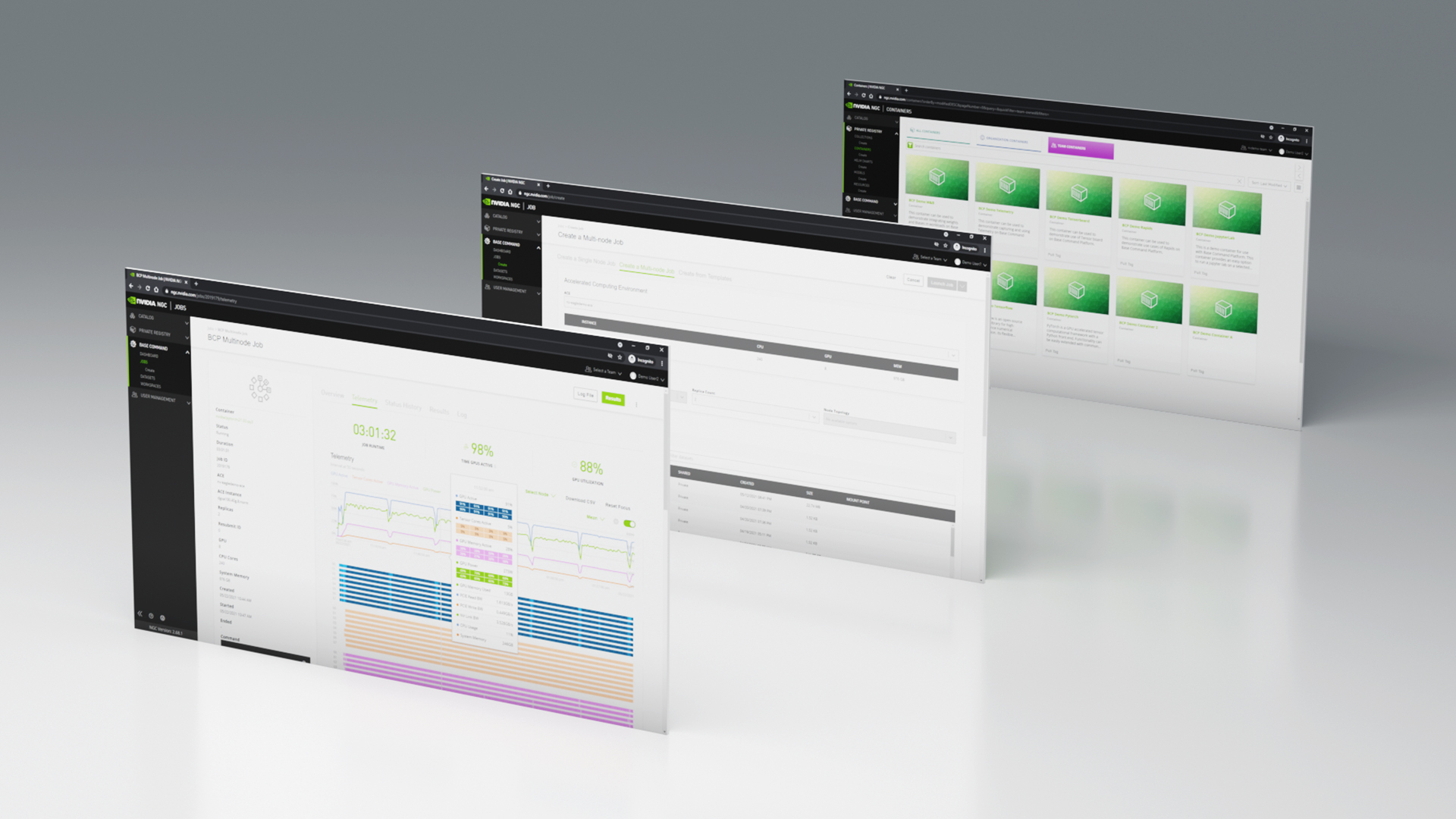
After a job has been launched, you are redirected to a page specific to that job, where the launch details are on the Overview tab. In fact, an equivalent CLI version of the launch form is available under the Command section.
Jobs are presented in a way that makes them easy to reproduce: either by copying a CLI representation or by cloning the job through the web interface. If ports were added to the job when launched, a URL endpoint is also available (Video 2).
Several additional tabs are present for a scheduled, running, or completed job:
- Telemetry: Key performance metrics for a job over time.
- Status History: A list of states that the job and associated replicas have been in.
- Results: A way to view the files that have been saved to a job’s results directory.
- Log: Searchable, live access to a job’s stdout output.
After a job completes, the job-specific page is still accessible and can be used as a reference for future jobs, or further debugging if something didn’t work out as intended. The results directory and log files from the job can be easily retrieved. Depending on how the job was written, the desired job artifacts could be in a workspace instead of the results directory.
Base Command Platform provides CLI support for downloading data from a workspace. The resulting artifacts from a job can then be uploaded into Base Command Platform, either made public or kept in the private registry for the org. It provides the starting point for further experimentation in Base Command Platform or a critical component for a model deployed elsewhere.
For more information, see Managing Jobs.
MLOps integration using the NGC API
You can further augment and extend Base Command Platform capabilities with external software integration through the documented NGC API.
The NGC API can be used for workflow integration or dashboards outside of Base Command Platform, such as third-party MLOps platforms and tools. MLOps software and service providers that have integrated their unique offerings with Base Command Platform include Weights & Biases and Rescale.
As Base Command Platform features evolve and expand, the NGC API enables new and existing software ecosystems to integrate its strengths into other purpose-built solutions.
Conclusion
Base Command Platform is one of the key NVIDIA tools for making AI infrastructure accessible to developers. To get a hands-on sense of how Base Command Platform works, NVIDIA offers a series of labs through NVIDIA LaunchPad. Some labs cover specific use cases around natural language processing and medical imaging, and others are tailored toward gaining experience with Base Command Platform capabilities.
Learn how to use NVIDIA Base Command Platform to accelerate your containerized AI training workloads.