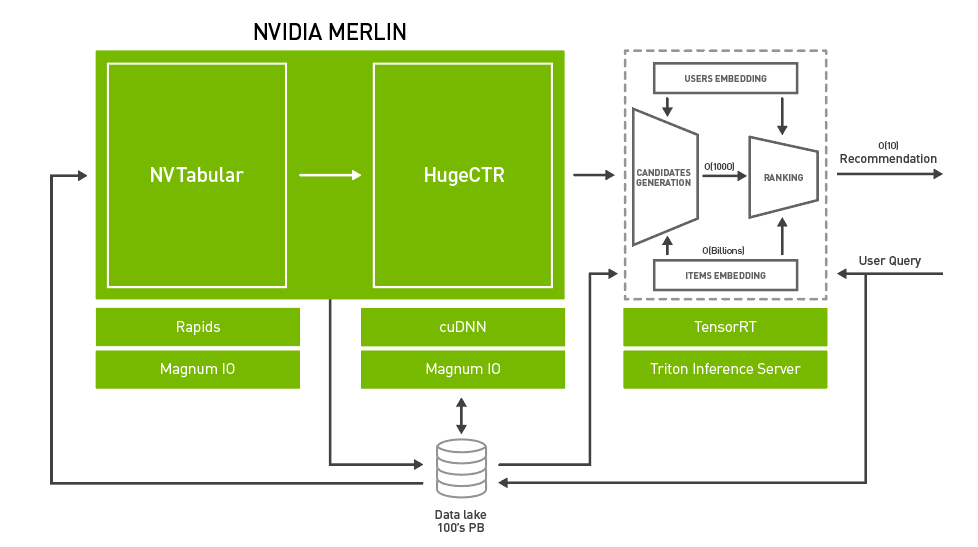
Recommendation models have progressed rapidly in recent years due to advances in deep learning and the use of vector embeddings. The growing complexity of these models demands robust systems to support them, which can be challenging to deploy and maintain in production.
In the paper Monolith: Real Time Recommendation System With Collisionless Embedding Table, ByteDance details how they built a recommendation system to support online training, rolling embedding updates, fault tolerance, and more.
This post details offline, online, and online large-scale recommendation system architectures. With a focus on deployment, we use a building block framework, NVIDIA Merlin, and a real-time data layer, Redis, to construct examples of end-to-end recommendation systems. Near the end, we provide cloud deployment instructions and managed-Redis options for production readiness and simplified architecture.
Download the code in the RedisVentures/Redis-Recsys GitHub repository and view related assets to follow along with each example. Terraform scripts and ansible playbooks are provided to help deploy this infrastructure on Amazon Web Services.
Join us at GTC 2023 for an upcoming talk, Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton, to gain tips on optimizing your recommendation system to achieve lower latency.
Recommendation system architecture
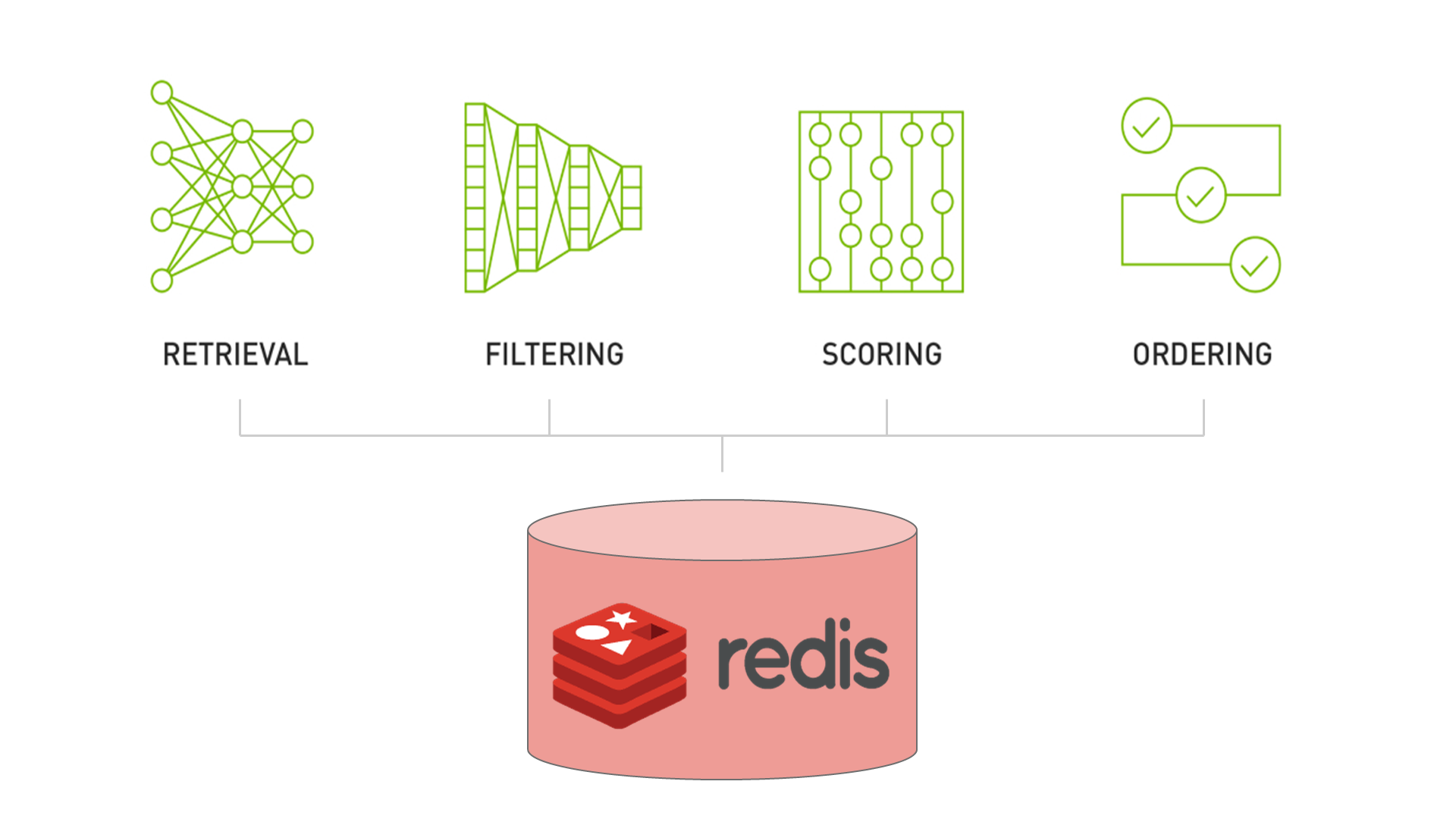
NVIDIA Merlin recommendation systems rely on a four-stage pattern as discussed in Recommender Systems, Not Just Recommender Models:
- Retrieval of a reasonably relevant set that contains the items that the user will eventually engage with.
- Filtering unwanted items that would be nearly impossible to enforce by the model.
- Scoring (or ranking) interest that a user may have with a set of items.
- Ordering the items to align the output of the model with other needs or constraints of the business.
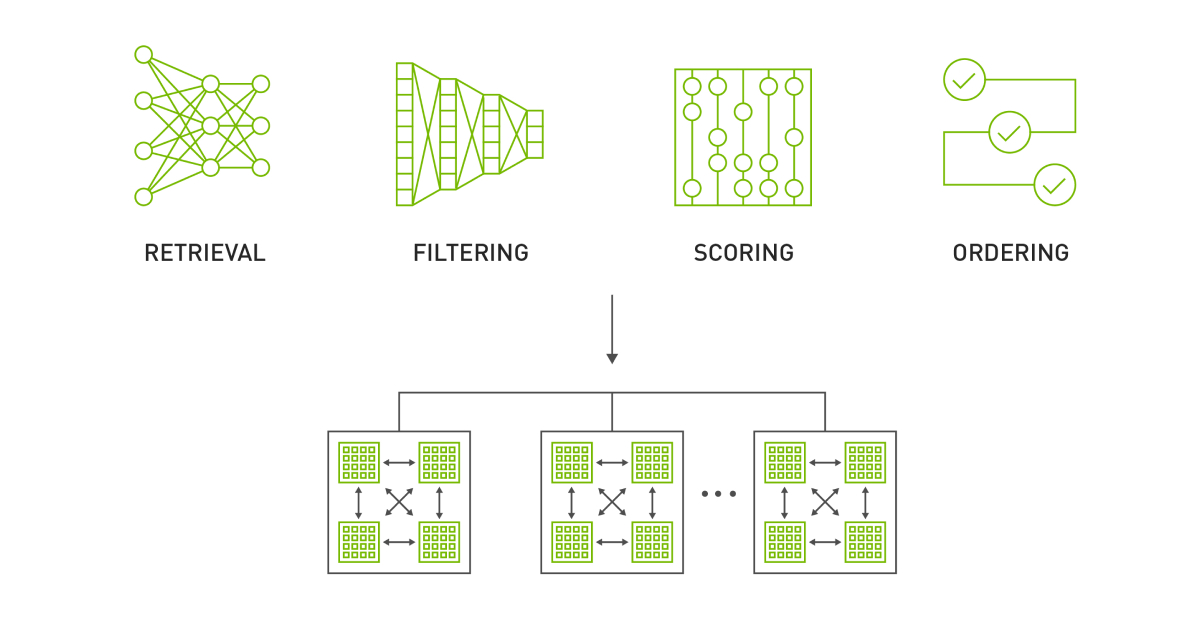
These four stages of retrieval, filtering, scoring, and ordering make up a design pattern covering what most recommender systems look like in production (Figure 1). For this post, we use scoring and ranking synonymously. We focus only on the retrieval and scoring stages as they are especially computation-intensive stages of a recommender system.
Retrieval phase
The retrieval process is commonly fast but coarse-grained. A relevant subset is selected from a large pool of potential candidates. Efficiency is valued over precision in this step.
In modern retrieval systems, catalogs of candidates are turned into dense embeddings created by passing all potential items through a deep learning model. When indexed using RediSearch or FAISS, millions of embeddings can be compared, and the most similar candidate embeddings can be retrieved at low latency.
Ranking phase
In the ranking process, precision is heavily favored over efficiency. Thus, ranking models are often more computationally complex than in the retrieval stage. Thanks to deep learning advances, the ranking phase can encompass more data than previously possible.
Models like deep learning recommendation model (DLRM), produced by Meta, are used in the ranking stage and can learn to rank millions of candidates for a given user. However, inputs are constrained to the order of a few thousand candidates.
Large-scale ranking systems often apply two or more sub-phases, coarse ranking and fine-ranking or re-ranking, to leverage more sophisticated methods or inject additional information to influence the final output. Combined, they further narrow down the number of candidates as computational costs increase.
For more information about recommendation system architecture, see System Design for Recommendations and Search. This post covers a few examples deployed by top companies.
While we use the term offline to refer to the deployment architecture of the overall recommendation system, Eugene Yan refers to offline as the model training stage.
Offline recommendation systems
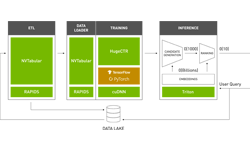
Offline recommendation systems use batch computing to process large datasets and store recommendations for later retrieval.
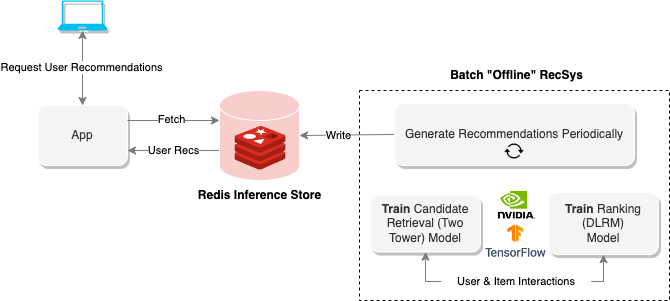
Batch computing is especially useful for developers who cannot afford the complexity of hosting a live multi-stage recommendation system or who must get something up and running quickly. These systems are well-suited to business objectives that must only be refreshed at some interval but which necessitate high precision and therefore, extra compute time. Examples include periodic newsletters or e-mail campaigns.
Figure 2 shows the offline architecture where Redis is purely used for recommendation storage and retrieval. The notebook Offline Batch Recommender System demonstrates how to create a system like this for the Alibaba Click and Conversion Prediction dataset.
Retrieval: two-tower
The candidate retrieval model is a two-tower neural network architecture. The user tower models the user preferences, while the item tower models the item characteristics.
The notebook example uses negative sampling during training. Instead of using explicit feedback, such as user ratings or scores, the model uses implicit feedback, such as user interactions or clicks. The trained embeddings are used to narrow down the full item catalog to those most likely to be interacted with by a given user. The embeddings can also be used for item-item or user-user similarity within other ecommerce use cases, such as content-based recommendations or customer segmentation.
Rank: DLRM
Ranking models are a type of machine learning model commonly used in recommendation systems to rank items based on relevance or likelihood of user interaction. These models can generate personalized recommendations by considering user preferences and past interactions, such as clicks, purchases, or ratings.
The Jupyter notebook example uses DLRM, a hybrid model architecture that scores and ranks user-item pairs. For more information about DLRM architecture, see the Exporting Ranking Models notebook.
Generating and serving recommendations
The final portion of the recommendation system is hosting the generated recommendations in a low-latency data layer. A key-value store, such as Redis, enables you to access the recommendations in near real-time without the complexity of hosting the infrastructure for an online recommendation system.
The next section explains how to take the pipeline just described and deploy a real-time serving layer for generating recommendations online.
Online recommendation systems
An online recommendation system generates recommendations on demand. As opposed to batch-oriented systems, scalability, and end-to-end latency (typically <100-300 ms) are often the most important factors.
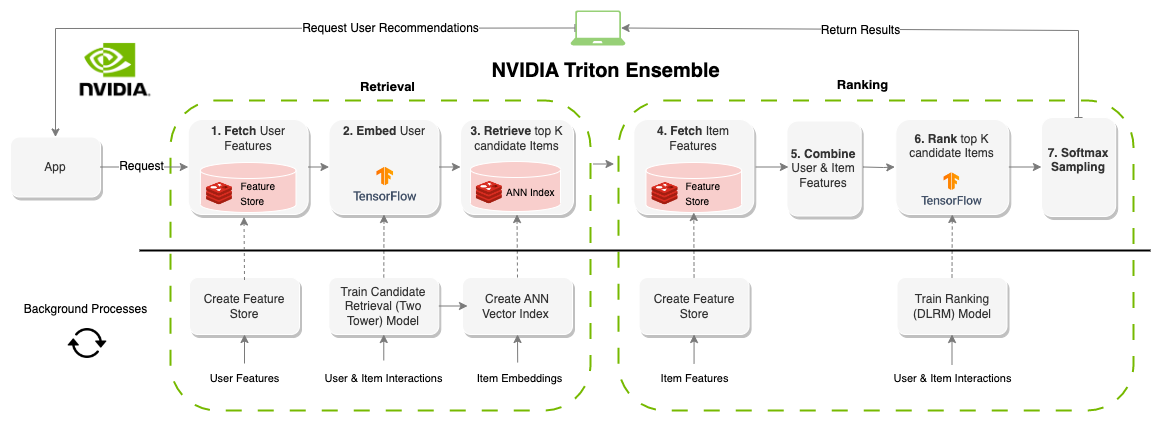
This section introduces the infrastructure required to build an online recommendation system with feature storage (Redis), orchestration (Feast), vector databases and search (Redis), and inference (NVIDIA Triton).
We then present a set of notebooks that outline how to tie this infrastructure together using the NVIDIA Triton inference server ensemble functionality.
Feature storage
The two widely deployed types of feature stores that closely mimic the dichotomy of recommendation systems are offline and online stores.
Offline feature store
An offline feature store is usually a durable, disk-based database with large capacity (>10 TB). All model features, including historical features, are kept in the offline store. Batch processing frameworks like Apache Spark are often used to materialize features from the offline store to an online feature store at some specified interval. Spark-Redis, for example, is frequently used to load features to Redis.
Online feature store
Online feature stores trade capacity for reduced latency, commonly keeping features in-memory. A subset of features is materialized into the online store from the offline store, such that the “freshest” features are maintained for serving. Online stores are directly queried in serving pipelines to provide machine learning models with enriched feature vectors for inference.
In this second example, Redis is used as an online feature store where user and item features are materialized from parquet files (offline store). Feast, a feature orchestration framework, is used to define the features, configure materialization, and query model features at runtime.
Serving embeddings
In the offline example, a two-tower model is used to encode users and items into embeddings. For online serving, however, the overall latency of the system can be reduced by only using the user tower and deploying a vector database to host and search through item embeddings.
As well as reduced latency, a vector database enables embeddings to be updated without disrupting query serving. The offline notebook saves the created item embeddings to file so that the online notebook can demonstrate how this system is set up.
Redis, in addition to being used as the online feature store, is also used as an approximate nearest neighbors index of the item embeddings with the RediSearch module. RediSearch added support for vector indices in version 2.4.
The notebook Building Online Multi-Stage Recsys Components shows how to set up Feast and Redis for feature storage and vector embedding search.
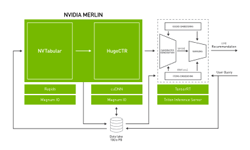
Serving real-time recommendations
NVIDIA Triton, an inference serving platform, has a number of backends to support different model types and pipelines. The ensemble backend enables you to define a number of steps to run in a directed acyclic graph (DAG). After Feast and Redis have been set up, you can define an NVIDIA Triton ensemble (Figure 3) that executes the recommendation system pipeline on demand, given a user_id value.
The Deploying Online Multi-Stage RecSys with Triton Inference Server notebook shows how to define the NVIDIA Triton ensemble and provides examples for how to query it using the NVIDIA Triton Python client.
Design considerations
Even though this system enables live recommendations, there are still a few design considerations to take into account.
First, user features must be regularly published from the offline to online feature store. For example, a user performing actions on the ecommerce site may see static recommendations unless feature materialization is happening frequently enough. However, if performed too often, the number of writes to Redis can degrade read throughput and slow down the serving pipeline. Finding the balance is key.
Second, the trained models must be monitored for feature drift. As features are updated from what the training set contained, the model performance may change over time. To maintain performance, models should be retrained and updated over time. In addition, the embeddings stored in the vector index should be updated when the models are updated. With Redis, incremental vector updates can be made directly to the index, or a new vector index can be created in the background and swapped in with the FT.ALIASADD command.
Online, large-scale
Large enterprises often have millions of users and items. The entire embedding table of a model may not fit on a single GPU.
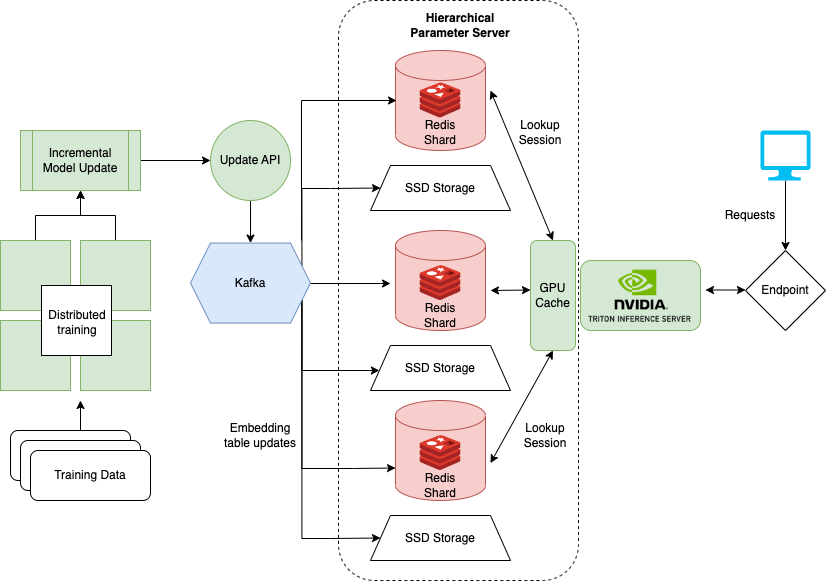
For this, NVIDIA Merlin created the HugeCTR backend, which facilities distributed training, updates, and recommendation model serving
The notebook Large-Scale Recommender Models focuses on HugeCTR deployment and provides a pretrained version of DLRM that can be used for the example. For more information about distributed training with HugeCTR, see Scaling Recommendation System Inference with Merlin Hierarchical Parameter Server.
Serving with HugeCTR
The DLRM model deployed in the referenced notebook is the same as the ranking model online recommendation system from the previous section. The ranking stage is explored further in this section to describe how HugeCTR enables the level of capacity required at the ranking stage of a multi-stage recommendation system.
HugeCTR makes it possible to have ranking models that account for millions of user-item interactions creating precise yet computationally expensive models. As mentioned, the ranking stage is usually slower and more precise than retrieval, typically accounting for a large portion of the available time budget allotted to a given use case.
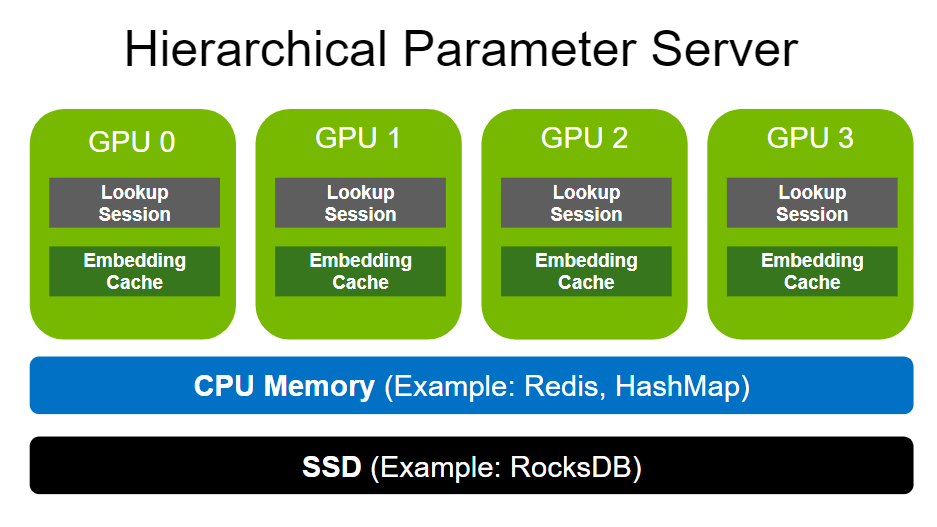
Hierarchical parameter server
HugeCTR distributes embeddings across multiple servers by using Hierarchical Parameter Server (HPS), shown in Figure 4. HPS is a tiered memory system that caches embeddings across three different locations, progressively trading off speed for capacity.
GPU cache layer
The GPU cache holds the most frequently accessed embeddings closest to where they will be used for inference. With embeddings already on the GPU, data movement latencies are reduced at inference time. Typically, the access pattern for embeddings mimics the power law, and the maximum benefit is obtained by filling up the GPU cache with as many embeddings as possible.
CPU memory layer
The CPU memory layer is larger in capacity than the GPU cache. However, data must be moved to the GPU before inference and it is slower to access at inference time. The CPU memory layer in HPS implements multiple approaches, such as distributed hash maps. The notebook example uses Redis to cache embeddings in memory. HugeCTR fully supports Redis clusters to distribute embedding table memory across servers.
SSD layer
The SSD layer is the largest and slowest layer in HPS. The entire embedding table is persisted in the SSD layer. This layer provides the guarantee that a distributed embedding table will not be lost in the case of a failure scenario, as each server contains an entire set of the embedding tables for all models.
Rolling updates
Updating embeddings is a necessary part of hosting an online recommendation system. In the online recommendation system example, we relied on Redis functionality to update in the background. However, the updates did not address the embedding table used by the trained DLRM model.
Instead, the model must be updated to avoid feature and model drift issues. Updates can be achieved by uploading a new version of the DLRM to NVIDIA Triton. However, large-scale models such as those trained with the HugeCTR framework are not easily updated as they can reach terabytes in total size.
To address large-scale models, NVIDIA implemented a rolling update system using Kafka, which sends updated embeddings as messages in a Kafka pipeline to the NVIDIA Triton server running the HugeCTR backend. As a result, online training of the DLRM model can occur in tandem with serving. This online, large-scale architecture closely resembles the architecture discussed in Monolith: Real-Time Recommendation System with Collisionless Embedding Table.
Cloud-based deployment
The accompanying notebooks provide examples of how to configure and deploy NVIDIA Triton with the HugeCTR backend and HPS with Docker (local) and with Terraform on AWS (cloud). However, in some cases, self-managed deployment of the HPS infrastructure may be less desirable.
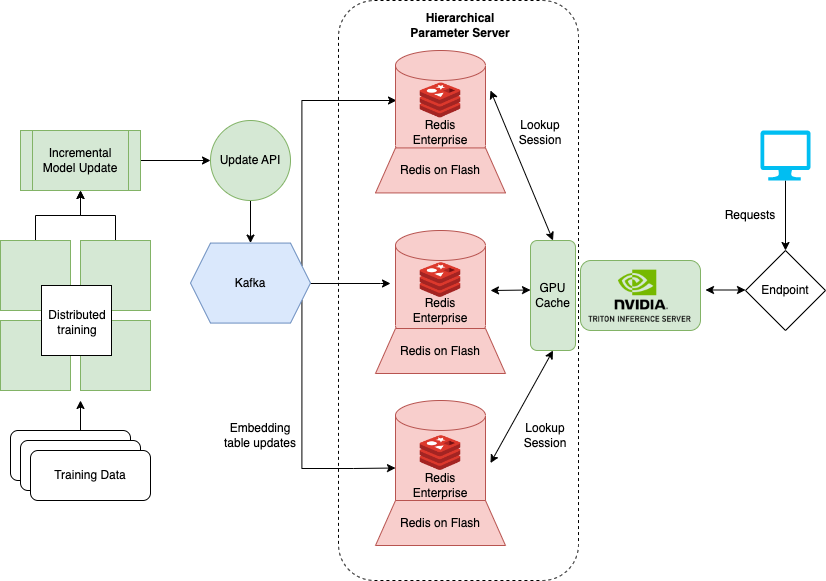
There are a number of Redis providers that launch and manage much of the infrastructure needed to run HPS at scale. One option, Redis Enterprise, provides a managed version of Redis deployed in the cloud and simplifies the infrastructure of HPS.
In Figure 5, the RocksDB-based SSD layer is replaced by the Redis Enterprise flash capability (RoF). With RoF, you can tune the ratio between SSD and flash directly in Redis without needing to re-deploy the HugeCTR model in NVIDIA Triton. This can be beneficial when adjusting for peaks and valleys in traffic.
With the existing RocksDB layer, each model’s embedding table is stored on every inference node to enhance system availability. That way, in case of a catastrophic event, the model parameters and inference service can be recovered, assuming at least one compute instance is alive. Instead, RoF reduces overall HPS storage requirements by distributing replication across the shards of a Redis database.
Redis Enterprise provides SLAs for failover times, availability (99.999%), active-active geo distribution, and scalable IOPS by further sharding the database. The number of subscribers for Kafka messages to update the embeddings is also reduced to a single endpoint. Provided this architecture, the entire server becomes simpler and easier to maintain.
The RedisVentures/Redis-Recsys GitHub repository provides Terraform scripts and Ansible playbooks to launch this infrastructure on AWS.
Summary
This post describes three different use cases for using the NVIDIA Merlin framework to create recommendation systems with Redis as a real-time data layer. Each use case provides low latency solutions even as data scales, especially for computationally complex applications.
In an upcoming talk at GTC, Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton, ways to improve overall recommendation system performance will be discussed. For more information about these use cases, contact sam.partee@redis.com or follow me on Twitter @sampartee.