CUDA is the software development platform for building GPU-accelerated applications, providing all the components you need to develop applications that use NVIDIA GPUs. CUDA is ideal for diverse workloads from high performance computing, data science analytics, and AI applications. The latest release, CUDA 11.3, and its features are focused on enhancing the programming model and performance of your CUDA applications.
CUDA 11.3 has several important features. In this post, I offer an overview of the key capabilities:
- CUDA programming model
- CUDA Graph enhancements
- Stream-ordered memory allocator enhancements
- Language support: CUDA
- C++ support enhancements
- Python support
- Compiler enhancements
Download CUDA 11.3 today.
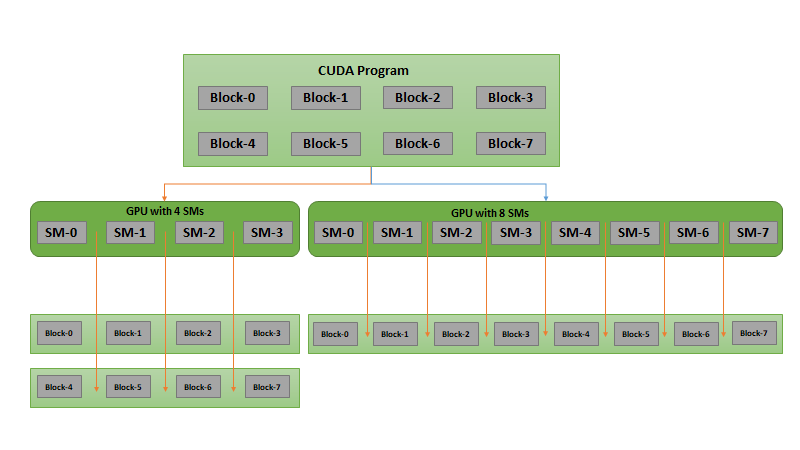
CUDA programming model enhancements
With every CUDA release, NVIDIA continues to enhance the CUDA programming model to enable you to get the most out of NVIDIA GPUs, while maintaining the programming flexibility of the higher-level APIs. In this release, we extended several of the CUDA APIs to improve the ease-of-use for CUDA graphs and enhance the stream-ordered memory allocator feature introduced in 11.2 among other update features.
CUDA Graphs
A graph is a series of operations, such as kernel launches, connected by dependencies, which is defined separately from its execution. This allows a graph to be defined once and then launched repeatedly, thus reducing overhead. CUDA graphs were introduced in CUDA 10.0 to allow work to be defined as graphs rather than single operations. For more information, see CUDA Graphs and Getting Started with CUDA Graphs.
Subsequent CUDA releases have seen a steady progression of new features. CUDA 11.3 introduces new features to improve the flexibility and the experience of using CUDA Graphs, such as:
- Stream capture composability
- User objects
- Debug API
There are two ways to create CUDA graphs: construct the graph from scratch using graph APIs or use stream capture, which wraps a section of the application code and records the launched work from CUDA streams into a CUDA graph.
The new enhancements provide mutable access to the graph and to the set of dependencies of a capturing stream while capture is in progress, enabling new use patterns. You can intermix native graph node creation with stream capture more easily in the same graph. You can also pipeline tasks in new ways with the event-based dependency mechanics. Such access to the graph handle is required for the next feature, user objects.
User objects
Dynamic resources referenced by a graph must persist for the lifetime of the graph and until all executions have completed. This can be particularly challenging with stream capture, when the code responsible for the resource, such as a library, is not the same code managing the graph, such as the application code calling a library inside stream capture. User objects is a new feature to assist with the lifetime management of such resources in graphs by assisting with reference-counting the resource.
The following pseudo-code example shows how you can use the CUDA user object and the corresponding APIs to address this. The cudaUserObjectCreate API provides the mechanism to associate a user-specified, destructor callback with an internal refcount for managing a dynamic resource.
Object *object = new Object; // Arbitrary C++ object cudaUserObject_t cuObject; // Template to wrap a delete statement in an extern "C" callback for CUDA: cudaUserObjectCreate(&cuObject, object); // Transfer our one reference (from calling create) to a graph: cudaGraphRetainUserObject(graph, cuObject, cudaGraphUserObjectMove); // No more references owned by this thread; no need to call release. cudaGraphInstantiate(&graphExec, graph); // Retains an additional reference cudaGraphDestroy(graph); // graphExec still owns a reference cudaGraphLaunch(graphExec, stream); // graphExec has access while executing // The execution is not synchronized yet, so the release may be deferred past the destroy call: cudaGraphExecDestroy(graphExec); cudaStreamSynchronize(0); // The final release, and the call to the destructor, are now queued if they have not already executed. This completes asynchronously.
For more information, see CUDA User Objects.
Debug API
The new graph debug API provides a fast and convenient way to gain high-level understanding of a given graph by creating a comprehensive overview of the entire graph, without you calling individual API actions like the following to compose the graph:
cudaGraphGetNodescudaGraphGetEdgescudaGraphHostNodeGetParamscudaGraphKernelNodeGetParams
The single cudaGraphDebugDotPrint API can construct a detailed view of any uninstantiated graph, demonstrating the topology, node geometry, attribute configurations, and parameter values. Given a CUDA graph, it outputs a DOT graph, where DOT is a graph description language. This detailed view of the graph makes it easier for you to identify obvious configuration issues and enables you to create easy-to-understand bug reports that can be used by others to analyze and debug the issue. Combining this API with a debugger increases the usefulness, by isolating issues to specific nodes.
cudaGraphDebugDotPrint(CUgraph hGraph, const char *path, unsigned int flags);
Stream-ordered memory allocator
One of the highlights of CUDA 11.2 was the stream-ordered CUDA memory allocator feature that enables applications to order memory allocation and deallocation with other work launched into a CUDA stream. It also enables sharing memory pools across entities within an application. For more information, see Enhancing Memory Allocation with New NVIDIA CUDA 11.2 Features.
In CUDA 11.3, we added new APIs to enhance this feature:
- A pointer query to obtain the handle to the memory pool for those pointers obtained from an async allocator.
cuPointerGetAttributehas theCU_POINTER_ATTRIBUTE_MEMPOOL_HANDLEattribute to retrieve the mempool corresponding to an allocation. - Device query to check if mempool-based inter-process communication (IPC) is supported for a particular mempool handle type.
cuDeviceGetAttributehas anCU_DEVICE_ATTRIBUTE_MEMPOOL_SUPPORTED_HANDLE_TYPESattribute - Query mempool usage statistics that provide a way to obtain allocated memory details.
cuMemPoolhas attributes such as the amount of physical memory currently allocated to the pool. The sum of sizes of allocations that have not been freed can be queried using thecudaMemPoolGetAttributeAPI.
For more information, see Stream Ordered Memory Allocator.
Other programming model enhancements
CUDA 11.3 formally supports virtual aliasing, a process where an application accesses two different virtual addresses, but they end up referencing the same physical allocation, creating a synonym in the memory address space. The CUDA programming model has been updated to provide guidelines and guarantees for this previously undefined behavior. The Virtual Memory Management APIs provide a way to create multiple virtual memory mappings to the same allocation using multiple calls to cuMemMap with different virtual addresses, that is, virtual aliasing.
CUDA 11.3 also introduces a new driver and runtime API to query memory addresses for driver API functions. Previously, there was no direct way to obtain function pointers to the CUDA driver symbols. To do so, you had to call into dlopen, dlsym, or GetProcAddress. This feature implements a new driver API, cuGetProcAddress, and the corresponding new runtime API cudaGetDriverEntryPoint.
This enables you to use the runtime API to call into driver APIs like cuCtxCreate and cuModuleLoad that do not have a runtime wrapper. It also enables access to new CUDA features with the newer driver on older toolkits or requesting for a per-thread default stream version of a CUDA driver function. For more information, see CUDA Driver API and Driver Entry Point Access.
Language extensions: CUDA
We continue to enrich and extend the CUDA software environment through extensions to industry-standard programming languages. More recently, we’ve added enhancements to C++ and CUDA Python to help simplify the developer experience.
C++ support enhancements
NVIDIA C++ Standard Library (libcu++) is the C++ Standard Library for your entire system that is shipped with the CUDA toolkit. It provides a heterogeneous implementation of the C++ Standard Library that can be used in and between CPU and GPU code. It is an open-source project available on GitHub. A new version of libcu++ 1.4.1 is being released with the CUDA 11.3 toolkit release.
The CUDA 11.3 toolkit release also includes CUB 1.11.0 and Thrust 1.11.0, which are major releases providing bug fixes and performance enhancements. CUB 1.11.0 includes a new DeviceRadixSort backend that improves performance by up to 2x on supported keys and hardware. Thrust 1.11.0 includes a new sort algorithm that provides up to 2x more performance from thrust::sort when used with certain key types and hardware. The new thrust::shuffle algorithm has been tweaked to improve the randomness of the output. For more information, see CUB and Thrust.
Python support
NVIDIA is excited by the vast developer community demand for support of the Python programming language. Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. We’ve long been committed to helping the Python ecosystem use the accelerated computing performance of GPUs to deliver standardized libraries, tools, and applications. This is another step towards improved Python code portability and compatibility.
Our goal is to help unify the Python CUDA ecosystem with a single standard set of low-level interfaces, providing full coverage of and access to the CUDA host APIs from Python. We want to provide a foundation for the ecosystem to build on in unison, to allow interoperability amongst different accelerated libraries. Most importantly, we want to make it easy for you to use NVIDIA GPUs with Python, with Cython/Python wrappers for CUDA driver and Runtime APIs.
CUDA Python will be available on GitHub. For more information about the CUDA Python initiative, see Unifying the CUDA Python Ecosystem.
CUDA compiler
The CUDA 11.3 release of the CUDA C++ compiler toolchain incorporates new features aimed at improving productivity and code performance:
- cu++flt—A standalone demangler tool that allows you to decode mangled function names to aid source code correlation.
- NVRTC shared library versioning scheme—Relaxed to facilitate compatible upgrades of the library within a CUDA major release sequence.
- Built-in function alloca —Used to dynamically allocate dynamic memory out of the stack frame and now available for use in device code as a preview feature.
- CUDA C++ language—Extended to enable the use of the
constexprandautokeywords in broader contexts. - CUDA device linker— Also extended, with options that can be used to dump the call graph for device code along with register usage information to facilitate performance analysis and tuning.
For more information about these features, see Programming Efficiently with the NVIDIA CUDA 11.3 Compiler Toolchain.
NVIDIA Nsight developer tools
The NVIDIA Nsight toolset contains Nsight Systems, Nsight Compute, and Nsight Graphics to for better GPU profiling and performance optimizations. NVIDIA Nsight developer tools are seamlessly integrated into the software development environments for ease in execution and testing, with IDEs such as Microsoft Visual Studio and Eclipse.
Nsight VS Code is our latest addition to the series of toolsets. It is an extension to Visual Studio Code for CUDA-based applications. As VS Code is widely adopted by the developer community, Nsight VS Code supports the latest features.
Nsight Systems 2021.2 introduces support for GPU metrics sampling. These metrics chart an overview of GPU efficiency over time within compute, graphics, and IO activities:
- IO throughputs: PCIe, NVLink, and memory bandwidth
- SM utilization: SMs active, Tensor Core activity, instructions issued, warp occupancy, and unassigned warp slots
This expands Nsight Systems existing ability to profile system-wide activity to help you in the investigative work of tracking GPU workloads back to their CPU origins. It provides a deeper understanding of the GPU utilization levels and the combined effect of multiple processes.
Nsight Compute 2021.1 adds a new NVLink topology and properties, OptiX 7 API stepping, MacOS 11 Big Sur host support, and improved resource tracking capabilities for user objects, stream capture, and asynchronous sub allocations. These new features give you increased visibility into the dynamic performance behavior of your workloads and how you are using hardware and software resources.
For more information, see the following resources: