The NVIDIA A100, based on the NVIDIA Ampere GPU architecture, offers a suite of exciting new features: third-generation Tensor Cores, Multi-Instance GPU (MIG) and third-generation NVLink.
Ampere Tensor Cores introduce a novel math mode dedicated for AI training: the TensorFloat-32 (TF32). TF32 is designed to accelerate the processing of FP32 data types, commonly used in DL workloads. On NVIDIA A100 Tensor Cores, the throughput of mathematical operations running in TF32 format is up to 10x more than FP32 running on the prior Volta-generation V100 GPU, resulting in up to 5.7x higher performance for DL workloads.
Every month, NVIDIA releases containers for DL frameworks on NVIDIA NGC, all optimized for NVIDIA GPUs: TensorFlow 1, TensorFlow 2, PyTorch, and “NVIDIA Optimized Deep Learning Framework, powered by Apache MXNet”. Starting from the 20.06 release, we have added support for the new NVIDIA A100 features, new CUDA 11 and cuDNN 8 libraries in all the deep learning framework containers.
In this post, we focus on TensorFlow 1.15–based containers and pip wheels with support for NVIDIA GPUs, including the A100. We continue to release NVIDIA TensorFlow 1.15 every month to support the significant number of NVIDIA customers who are still using TensorFlow 1.x.
The NVIDIA TensorFlow 1.15.2 from 20.06 release is based on upstream TensorFlow version 1.15.2. With this release, we provide out-of-the-box support for TF32 on NVIDIA Ampere architecture GPUs while also enhancing the support for previous-generation GPUs, such as Volta and Turing. This release allows you to realize the speed advantage of TF32 on NVIDIA Ampere architecture GPUs with no code change for DL workloads. This release also includes important updates to automatic mixed precision (AMP), XLA, and TensorFlow-TensorRT integration.
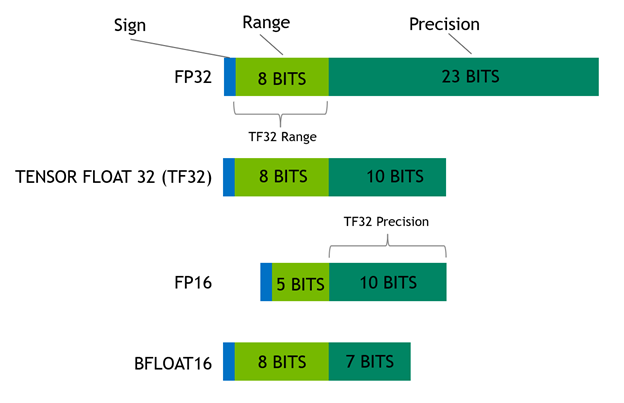
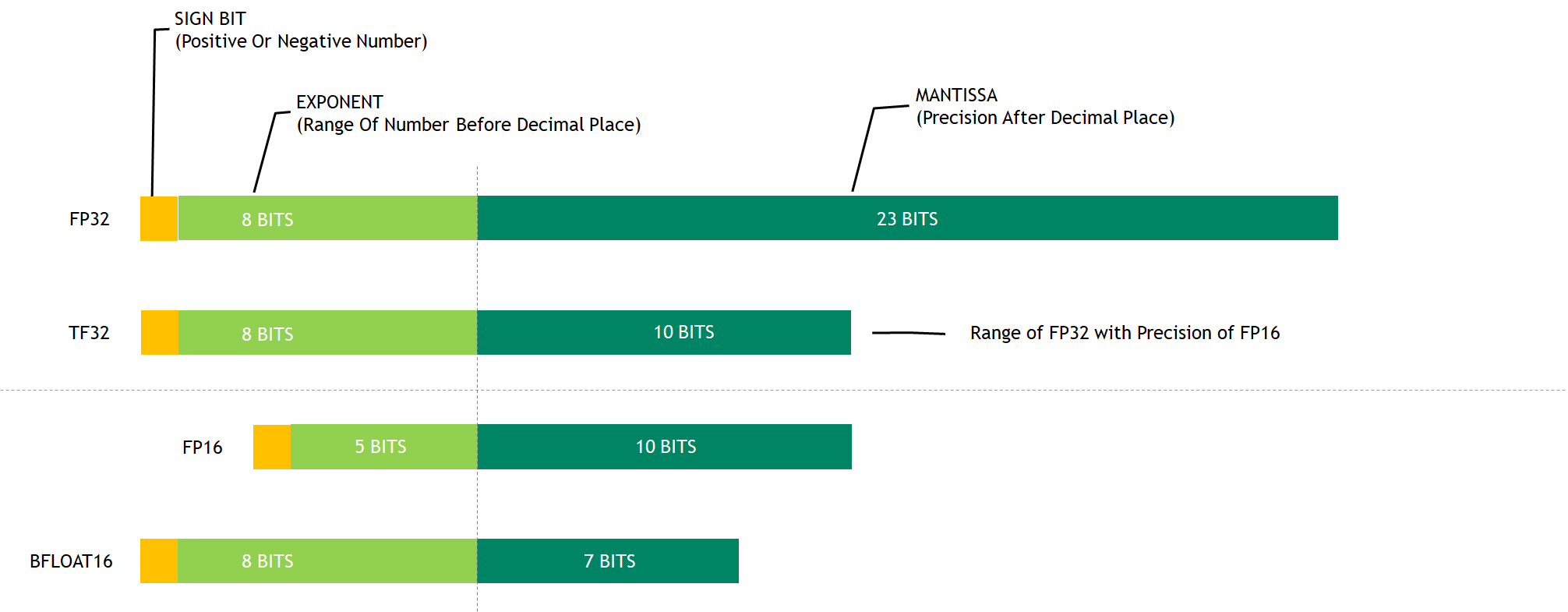
Numerical precisions supported by NVIDIA A100
Deep neural networks (DNNs) can often be trained with a mixed precision strategy, employing mostly FP16 but also FP32 precision when necessary. This strategy results in a significant reduction in computation, memory, and memory bandwidth requirements while most often converging to the similar final accuracy. For more information, see the Mixed Precision Training whitepaper by NVIDIA Research.
NVIDIA Tensor Cores are specialized arithmetic units on NVIDIA Volta and newer generation GPUs. They can carry out a complete matrix multiplication and accumulation operation (MMA) in a single clock cycle. On Volta and Turing, the inputs are two matrices of size 4×4 in FP16 format, while the accumulator is in FP32.
The third-generation Tensor Cores on Ampere support a novel math mode: TF32. TF32 is a hybrid format defined to handle the work of FP32 with greater efficiency. Specifically, TF32 uses the same 10-bit mantissa as FP16 to ensure accuracy while sporting the same range as FP32, thanks to using an 8-bit exponent.
A wider representable range matching FP32 eliminates the need of a loss-scaling operation when using TF32, thus simplifying the mixed precision training workflow. Figure 1 shows a comparison between various numerical formats.
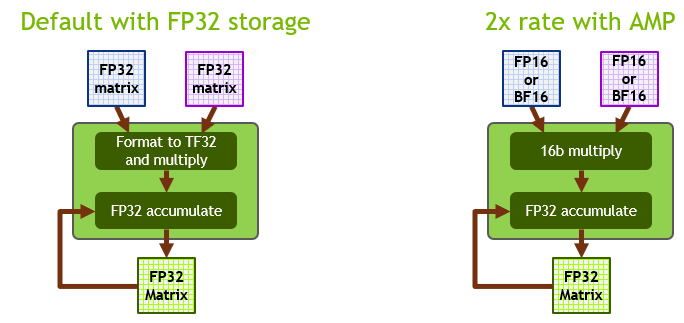
On Ampere Tensor Cores, TF32 is the default math mode for DL workloads, as opposed to FP32 on Volta/Turing GPUs. Internally, when operating in TF32 mode, Ampere Tensor Cores accept two FP32 matrices as inputs but internally carry out matrix multiplication in TF32 format. The result is accumulated in an FP32 matrix.
When operating in FP16/BF16 mode, Ampere Tensor Cores accept FP16/BF16 matrices instead, and accumulate in an FP32 matrix. FP16/BF16 mode on Ampere provides 2x throughput compared to TF32. Figure 2 shows these modes of operation.
TF32 is designed to bring the processing power of NVIDIA Tensor Cores technologies to all DL workloads without any required code changes. For more savvy developers who wish to unlock the highest throughput, AMP training with FP16 remains the most performant option and yet can be enabled easily with either no code change (when using the NVIDIA NGC TensorFlow container) or just a single line of extra code.
Our extensive experimentation on a wide range of network architectures has shown that any network that can be trained successfully to convergence with AMP on FP16/BF16 can also be trained to convergence with TF32. In such cases, the final TF32-trained model accuracy is comparable with those trained with FP32.
Enhancements to TensorFlow 1.15.2
TensorFlow 1.15.2 offers the following enhancements:
- TF32 support
- AMP
- XLA
- TensorFlow-TensorRT integration
TF32 support
NVIDIA TensorFlow 1.15.2 from 20.06 release uses Ampere TF32 capabilities out-of-the-box to accelerate all DL training workloads. This is the default option and requires no code change from developers. On pre-Ampere GPU architectures, FP32 is still the default precision.
You can also change the default math mode to FP32 on Ampere GPUs, by setting an environment variable:
export NVIDIA_TF32_OVERRIDE=0
This option is not recommended. Use it primarily for debugging purposes.
Automatic mixed-precision training
AMP training with FP16 remains the most performant option for DL training. For TensorFlow, AMP training was integrated after TensorFlow 1.14, allowing practitioners to easily carry out mixed precision training, either programmatically or by setting an environment variable.
Use a single API call to wrap the optimizer:
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
This change applies automatic loss scaling to your model and enables automatic casting to half precision, as demonstrated in the Mixed Precision Training of CNN example.
Use the following command to enable an environment variable in the NVIDIA NGC TensorFlow 1 container:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
This automatically applies mixed precision training to all TensorFlow workloads. For more information about carrying out manual mixed precision training, see Tensor Core Math.
XLA
XLA is a DL graph compiler for TensorFlow. In native TensorFlow, each layer of the network is processed independently. In contrast, XLA enables clustering of parts of the network into “sub-graphs” that can be optimized and compiled. This provides performance benefits at the cost of some compilation overhead. Figure 3 shows the workflow for XLA.
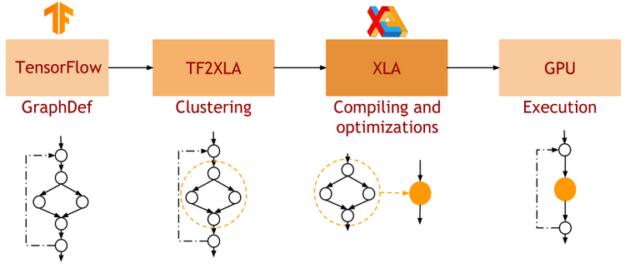
When executing on GPU, XLA carries out optimizations such as the following:
- Kernel fusion: Bandwidth-bound kernels with a consumer/producer relationship are vertically and horizontally fused into a single CUDA kernel. This improves performance by reducing access to global memory and provides most of the performance benefits observed.
- Calls to optimized library kernels: XLA-GPU targets highly optimized and performance-tuned cuDNN/cuBLAS kernels and combines multiple operators into a single optimized cuDNN/cuBLAS kernel.
For more information about XLA:GPU, see XLA Best Practices in the Deep Learning Frameworks documentation.
TensorFlow-TensorRT integration
NVIDIA TensorRT is an SDK for high-performance, DL inference. It includes a DL inference optimizer and runtime that delivers low latency and high throughput for DL inference applications.
TensorRT is tightly integrated into TensorFlow 1. We call it TensorFlow-TensorRT integration (TF-TRT). In TF version 1.15, it forms part of the tensorflow.python.compiler package. A trained neural network can be easily converted to a TF-TRT model with a simple API call, as shown in the following code block.
from tensorflow.python.compiler.tensorrt import trt_convert as trt converter = trt.TrtGraphConverter( input_saved_model_dir=input_saved_model_dir, precision_mode=trt.TrtPrecisionMode. ) converter.convert() converter.save(output_saved_model_dir)
TF-TRT can convert models into different precisions: FP32, FP16, and INT8. In the case of INT8, a small calibration dataset needs to be fed through the network to determine the best quantization parameters. When you convert a model from FP32 to INT8, TF-TRT offers up to 11x inference speedup on the Turing-generation T4 GPU. For more information about TF-TRT, see GTC 2020: TensorRT inference with TensorFlow 2.0.
When you convert the model to FP32 on Ampere, the internal math mode that TF-TRT employs is TF32 and does not require any code intervention.
Getting started with TensorFlow 1.15.2
NVIDIA TensorFlow 1.15.2 from the 20.06 release is available either as an NGC Docker image or through a pip wheel package.
Pulling the NGC Docker image
The NVIDIA TensorFlow release can be easily accessed by pulling an NGC Docker container image. Use the following command:
docker pull nvcr.io/nvidia/tensorflow:20.06-tf1-py3
This Docker container image includes all the required TensorFlow-GPU dependencies, such as CUDA, CuDNN, and TensorRT. It also includes the NCCL and Horovod libraries for multi-GPU and multi-node training and NVIDIA DALI for accelerated data preprocessing and loading.
Installing the pip wheel package
NVIDIA TensorFlow 1.15.2 from the 20.06 release can also be installed through a wheel package. When you use this installation method, NVIDIA TensorFlow only requires a bare metal environment with Ubuntu, such as Ubuntu 18.04, or a minimal Docker container, such as ubuntu:18.04. In addition, the NVIDIA graphic driver must also be available, and you should be able to call nvidia-smi to check the GPU status. All the other dependencies required for NVIDIA TensorFlow 1.15.2 from the 20.06 release are installed by the wheel package.
Basic software to install
Whether you are on bare metal or in a container, you may need to perform these operations:
apt update apt install -y python3-dev python3-pip git pip3 install --upgrade pip setuptools requests
Virtual environments
Some people use virtual environments to isolate pip packages from conflict. Conceptually, it is similar to a Docker image but it is essentially a separate installation directory with targeted search paths.
To set up the virtual environment:
pip install -U virtualenv virtualenv --system-site-packages -p python3 /venv
To start a virtual environment:
source /venv/bin/activate
Installing the index for the TensorFlow wheel
Installation of this index is required so that pip knows to go to the NVIDIA website to obtain the wheels. Otherwise, pip defaults to PyPI.org. Use the following command:
pip install nvidia-pyindex
Installing the TensorFlow wheel
By using the software, you agree to comply with the terms of the license agreement that accompanies the software. If you do not agree to the terms of the license agreement, do not use the software.
Use the following command:
pip install nvidia-tensorflow[horovod]
Verify that the packages are installed:
pip list | grep nvidia
The output should be as follows:
nvidia-cublas 11.1.0.213 nvidia-cuda-cupti 11.0.167 nvidia-cuda-nvcc 11.0.167 nvidia-cuda-nvrtc 11.0.167 nvidia-cuda-runtime 11.0.167 nvidia-cudnn 8.0.1.13 nvidia-cufft 10.1.3.191 nvidia-curand 10.2.0.191 nvidia-cusolver 10.4.0.191 nvidia-cusparse 11.0.0.191 nvidia-dali 0.22.0 nvidia-dali-tf-plugin 0.22.0 nvidia-horovod 0.19.1 nvidia-nccl 2.7.5 nvidia-pyindex 1.0.0 nvidia-tensorflow 1.15.2+nv20.6 nvidia-tensorrt 7.1.2.8
Verify that TensorFlow loads:
python -c 'import tensorflow as tf; print(tf.__version__)'
The output should be:
1.15.2
Verify that the GPU is seen by TensorFlow:
python -c "import tensorflow as tf; print('Num GPUs Available: ', len(tf.config.experimental.list_physical_devices('GPU')))"
The output should be something like the following:
2020-05-16 22:03:35.428277: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: name: Tesla V100-SXM2-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.53
Performance benchmarks
In this section, we discuss the accuracy and performance of TF32 on the NVIDIA A100, in comparison to FP32 and mixed precision training with AMP, when running in the NVIDIA TensorFlow 1.15.2 NGC container.
TF32 accuracy
TF32 matches FP32 results for any network trained successfully with FP16 or BF16 mixed precision. We have experimented with an extensive list of network architectures and have yet to see an exception.
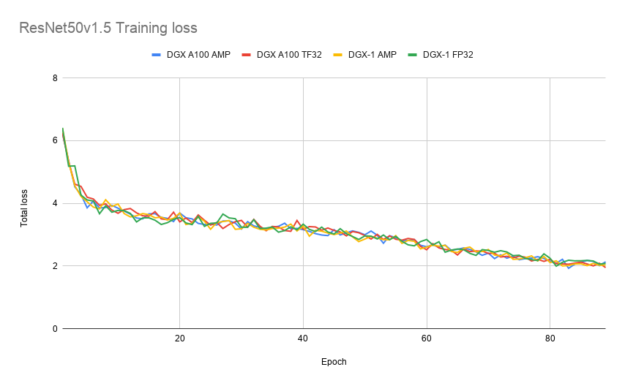
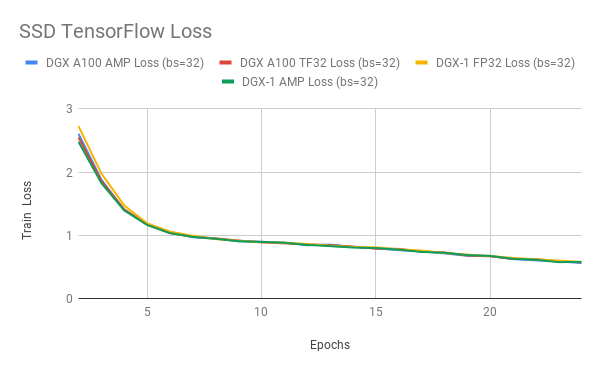
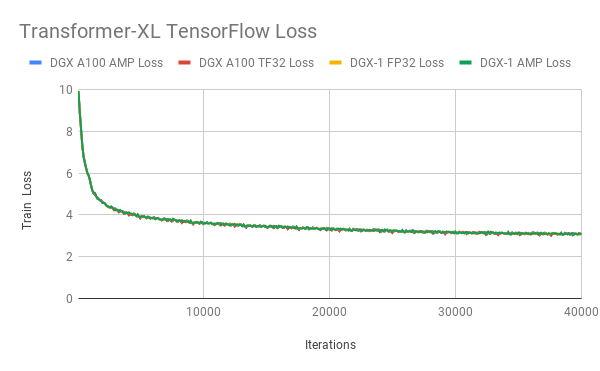
Figures 4-6 show the training loss curves for ResNet50, SSD, and Transformer-XL when trained with TF32, FP32, and AMP. TF32 produces comparable training curves in terms of stability and final accuracy. These results can be reproduced using the model scripts found at NVIDIA Deep Learning examples.
Performance: TF32 on NVIDIA A100
Figure 7 shows the speedup observed when training with TF32 on A100 in comparison to FP32 on V100, on a variety of network architectures. We observed typical throughput speedup of up to 6X while converging to the same final accuracy.
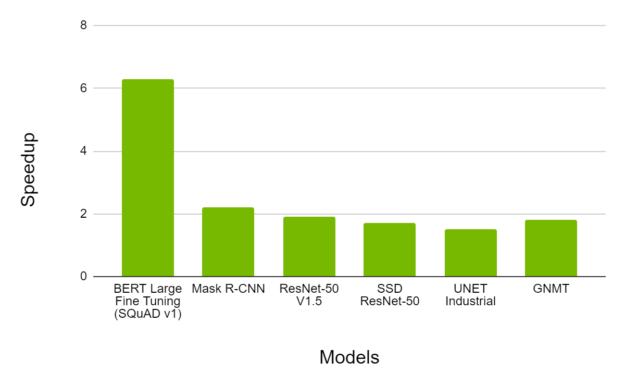
Performance: FP16 on NVIDIA A100
AMP with FP16 remains the most performant option for DL training on the A100. Figure 8 shows that, for various models, AMP on A100 provides a throughput speedup of up to 4.5X over AMP on V100, while converging to the same final accuracy.
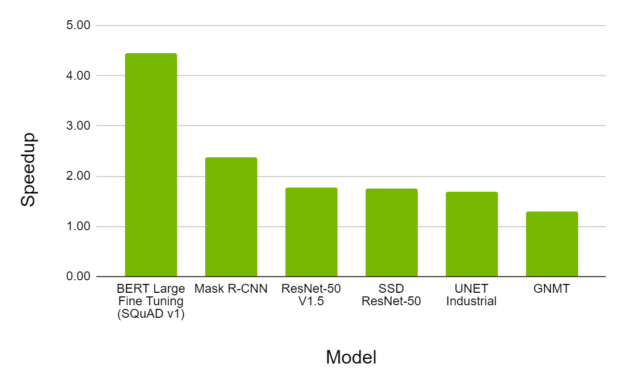
Call to action
The NVIDIA A100 GPU is packed with advanced features that provide a healthy speedup to all DL training workloads.
You can try NVIDIA TensorFlow 1.15.2 from 20.06 with the NVIDIA Deep Learning examples and experience the benefits of TF32, XLA, and TensorFlow-TensorRT integration on the Ampere generation NVIDIA A100 GPU. NVIDIA TensorFlow is available from the TensorFlow NGC container version 20.06 and is also released as open source code at https://github.com/NVIDIA/tensorflow.