At Mobile World Congress Los Angeles, NVIDIA Co-founder and CEO Jensen Huang announced in his keynote – NVIDIA Riva, an SDK for building and deploying AI applications that fuse vision, speech, and other sensors into one system.
Introducing NVIDIA Riva, multimodal AI SDK
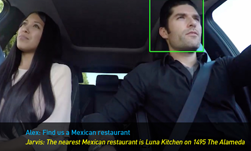
NVIDIA Riva offers a comprehensive workflow to build, train and deploy AI systems that uses speech and visual cues such as gestures and gaze in context. For example, lip movement can be fused with speech input to identify the active speaker. Gaze can be used to understand if the speaker is engaging the AI agent or other people in the scene. This enables simultaneous multi-user, multi-context conversations with the AI system that need a deeper understanding of the context.
The new SDK provides several base modules for speech tasks such as such as intent and entity classification, sentiment analysis, dialog modeling, domain and fulfillment mapping.
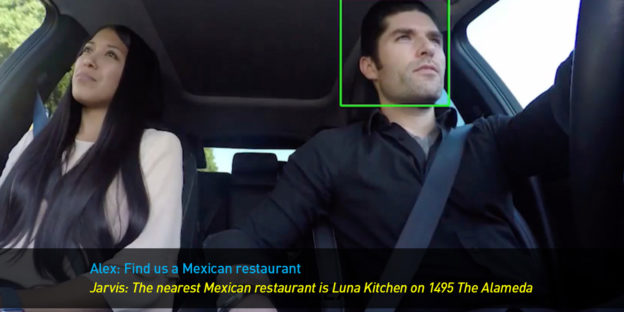
For vision, modules include person detection and tracking, detection of key body landmarks and body pose, gestures, lip activity and gaze.
With Riva, you can also use custom modules or fine-tune to adapt for your use case.
For edge and IoT use cases, Riva runs on the NVIDIA EGX stack, which is compatible with all commercially available Kubernetes infrastructure.
Availability
To learn more about the SDK and early availability, apply now for early access.









