Whether you are using GPU clusters in the cloud or using your own data center to train deep neural networks, leading deep learning frameworks rely on NVIDIA’s Deep Learning SDK libraries to accelerate the massive amount of computation required to achieve high accuracy with deep learning.
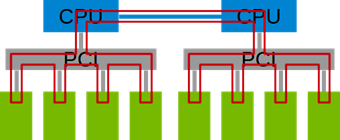
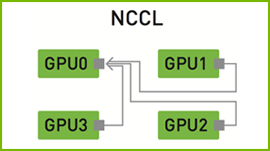
To learn more about the cuDNN and NCCL libraries that deliver high-performance training of neural networks across many multi-GPU systems check out the following talks, instructor-led labs and experts sessions at the GPU Technology Conference (GTC) next week about strategies you can employ to train models at scale to converge to your solution faster.
Talks
S7155 – OPTIMIZED INTER-GPU COLLECTIVE OPERATIONS WITH NCCL
S7601 – CAFFE2: A NEW LIGHTWEIGHT, MODULAR, AND SCALABLE DEEP LEARNING FRAMEWORK
S7554 – DEEP LEARNING APPLICATION DEVELOPMENT ON MULTI-GPU/ MULTI-NODE ENVIRONMENT
S7815 – BUILDING SCALE-OUT DEEP LEARNING INFRASTRUCTURE: LESSONS LEARNED FROM FACEBOOK A.I. RESEARCH
S7600 – CHAINERMN: SCALABLE DISTRIBUTED DEEP LEARNING WITH CHAINER
S7803 – DISTRIBUTED TENSORFLOW
S7569 – HIGH-PERFORMANCE DATA LOADING AND AUGMENTATION FOR DEEP NEURAL NETWORK TRAINING
Instructor-led labs
L7128 – DIY DEEP LEARNING: A HANDS-ON LAB WITH CAFFE2
L7104 – DEEP LEARNING USING MICROSOFT COGNITIVE TOOLKIT
Connect with the expert sessions:
H7131 – NCCL
H7122 – FRAMEWORKS FOR TRAINING DEEP NEURAL NETWORK
H7125 – CONNECT WITH THE EXPERTS: ADVANCED DEEP LEARNING
Recordings for all the talks will be available online after the conference.
Related resources
- GTC session: Model Parallelism: Building and Deploying Large Neural Networks
- GTC session: Get NVIDIA Certified at GTC
- GTC session: Live from GTC: A Conversation with DeepL
- SDK: RAPIDS Accelerator for Spark
- Webinar: How to Optimize AI Models for Faster Inference
- Webinar: Building and Running an End-to-End Machine Learning Workflow, 5x Faster